
October 20, 2023
The 5 Best Open-source AI Language Models
Artificial intelligence is taking over the world! Well, maybe not quite yet. But open source AI models are spreading like wildfire, bringing new capabilities to developers everywhere. We’ll count down the top 5 open source AI rockstars that are making waves. These open source projects are open for business – and they don’t even charge licensing fees! So plug in to the matrix and get ready to meet the AI models that are leading the open source machine revolution. Will one of them replace your job someday? Maybe! But for now, they’re here to make your applications smarter and your life a little easier. So all hail our new open source AI overlords! Just kidding, they’re not overlords quite yet. Let’s get to the list!

Above is an Alpaca Leaderboard. As you can see some open source models are now becoming as good as closed source.
The leaderboard also shows the length of the output text generated by each model. The models with the longest output text are generally those that were fine-tuned on GPT-4. This is because GPT-4 is a large language model, and it is able to generate more complex and informative text than smaller language models.
Llama70b-v2
First up, we’ve got LLaMA 70b-v2. LLaMA 2.0 is the next generation of the open-source large language model developed by Meta and Microsoft. It’s available for free for both research and commercial use. This groundbreaking AI model has been designed with safety in mind; it’s remarkably inoffensive. In fact, it errs on the side of caution so much that it may even refuse to answer non-controversial questions. While this level of cautiousness may increase trust in AI, it does beg the question: could making AI ‘too safe’ inhibit its capabilities?
By making LLaMA 2.0 openly available, it can benefit everyone, granting businesses, startups, entrepreneurs, and researchers access to tools at a scale that would be challenging to build themselves. In making these tools accessible, it opens up a world of opportunities for these groups to experiment and innovate. Yet, with this level of cautiousness and refusal to even slightly err, we will have to see if this could possibly limit the extent of creativity and innovation achievable.
The open approach to AI model development, especially in the generative space where the technology is rapidly advancing, is believed to be safer and more ethical. The community of developers can stress test these AI models, fast-tracking the identification and resolution of problems. This open-source model is expected to drive progress in the AI field by providing a potentially overly cautious, yet revolutionary model for developers to create new AI-powered experiences.
Vicuna-13b
Vicuna-33B is an auto-regressive language model based on the transformer architecture. It is an open-source LLM developed by LMSYS and fine-tuned using supervised instruction. The training data for Vicuna-33B was collected from ShareGPT, a portal where users share their incredible ChatGPT conversations. Vicuna-33B is trained on 33 billion parameters and has been derived from LLaMA like many other open-source models. Despite being a much smaller model, the performance of Vicuna-33B is remarkable. In LMSYS’s own MT-Bench test, it scored 7.12 whereas the best proprietary model, GPT-4 secured 8.99 points. In the MMLU test as well, it achieved 59.2 points and GPT-4 scored 86.4 points
Flan t5-xl
Flan-T5 XL is an enhanced version of T5, a family of large language models trained at Google, fine-tuned on a collection of datasets phrased as instructions. It has been fine-tuned in a mixture of tasks, and it includes the same improvements as T5 version 1.1.. Flan-T5 XL is a 3B parameter version of Flan-T5. The model was trained on a mixture of tasks, including text classification, summarization, and more1. Flan-T5 XL offers outstanding performance for a range of NLP applications, even compared to very large language models. However, it is important to note that Flan-T5 is not filtered for explicit content or assessed for existing biases, so it is potentially vulnerable to generating equivalently biased content
Stability AI
Generative AI in images has taken 2023 by storm. Stable Diffusion is a latent text-to-image diffusion model that can generate photo-realistic images based on any text input. It is a deep generative artificial neural network that uses a kind of diffusion model called a latent diffusion model2. The model was developed by the CompVis group at Ludwig Maximilian University of Munich and funded and shaped by the start-up company Stability AI. The technical license for the model was released by the CompVis group at LMU Munich. The model weights and code have been publicly released, and it can run on most consumer hardware equipped with a modest GPU with at least 8 GB VRAM. Stable Diffusion is not only capable of generating images but also modifying them based on text prompts. The model has been fine-tuned on a variety of datasets and tasks, including text classification and summarization1. The model is intended for research purposes only, and possible research areas and tasks include content creation, image synthesis, and more.
On July 27, 2023, Stability AI introduced Stable Diffusion XL 1.0 to its lineup. This “most advanced” release, as the company describes it, is a text-to-image model that promises to deliver vibrant and accurate colors with better contrast, shadows, and lighting compared to its predecessor. Available via open-source on GitHub as well as through Stability’s API and its consumer apps, ClipDrop and DreamStudio, the Stable Diffusion XL 1.0 model is designed to generate full 1-megapixel resolution images “in seconds,” across various aspect ratios, as announced by the company.
Joe Penna, Stability AI’s head of applied machine learning, spoke with TechCrunch about the improvements made in this new version. He noted that Stable Diffusion XL 1.0, which contains 3.5 billion parameters, essentially defining the proficiency of the model in generating images, signifies a major leap in the quality and speed of image generation.
Stable Diffusion XL 1.0 is an enhanced version of the original Stable Diffusion, a latent text-to-image model that can generate photo-realistic images based on any text input. The model weights and code have been publicly released, and it can run on most consumer hardware equipped with a modest GPU with at least 8 GB VRAM. Potential research areas and tasks for Stable Diffusion and its new release include content creation, image synthesis, and more. However, please do remember that this model is intended for research purposes only.
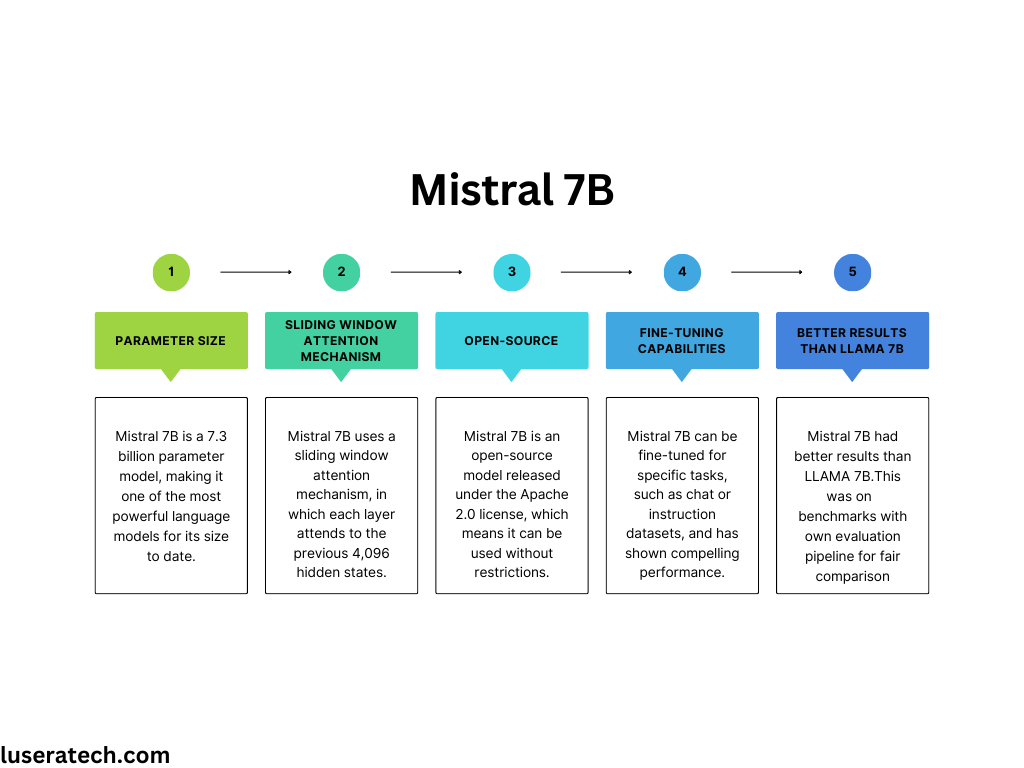
Mistral 7B
Mistral 7B is an open-source large language model (LLM) developed by Mistral AI, a startup in the AI sector. It is a 7.3 billion parameter model that uses a sliding window attention mechanism. Mistral 7B is designed to revolutionize generative artificial intelligence and offer superior adaptability, enabling customization to specific tasks and user needs.
Conclusion
The future of open-source AI models is nothing short of exciting. These AI models, in their diversity and inclusivity, could become the go-to solution for developers, innovators, and dreamers worldwide. Their proliferation is a testament to the power of collective intelligence and shared technological advancement. While each of these models boasts unique capabilities, they all share the common trait of being adaptable, scalable, and accessible. Fine-tuning, once a luxury, is now becoming commonplace, allowing these models to be meticulously tailored to suit specific uses while enhancing their performance. This development is set to democratize the AI landscape, making advanced tools available to even the most niche of projects. As we move forward, the influence of open-source AI models is set to only increase, paving the way for a future where technological barriers are a thing of the past, and innovation, creativity, and open collaboration are the new normal. So here’s to the rise of open-source AI – let’s embrace the revolution and see where it takes us