{kind=link}
Meta has unveiled a new AI tool called Code Llama that leverages the company’s Llama 2 large language model to generate, complete, and debug code. Code Llama aims to streamline developer workflows by automating routine coding tasks.
According to Meta, Code Llama can produce code based on text prompts, fill in incomplete code snippets, and identify and fix errors in existing code bases. In addition to a general Code Llama model, the company has released Code Llama-Python, which specializes in Python, and Code Llama-Instruct, which understands instructions in natural language.
Code Llama outperformed other publicly available AI coding assistants in benchmark testing, Meta claims. The different versions of Code Llama are tailored to specific use cases and are not interchangeable. Meta notes that the base Code Llama and Code Llama-Python should not be used for processing natural language instructions.
Code Llama is available in three model sizes, including a compressed version designed for low-latency applications. The tool will be released under the same community license as Llama 2, allowing free use for research and commercial projects.
Code Llama represents Meta’s entry into a rapidly evolving space of AI coding assistants. Competitors include GitHub’s Copilot, Amazon’s CodeWhisperer, and Google’s AlphaCode. The launch of Code Llama highlights the growing role of AI in augmenting and automating software development. According to Meta, these tools will allow programmers to focus more time on creative, strategic tasks.
How Code Llama Works
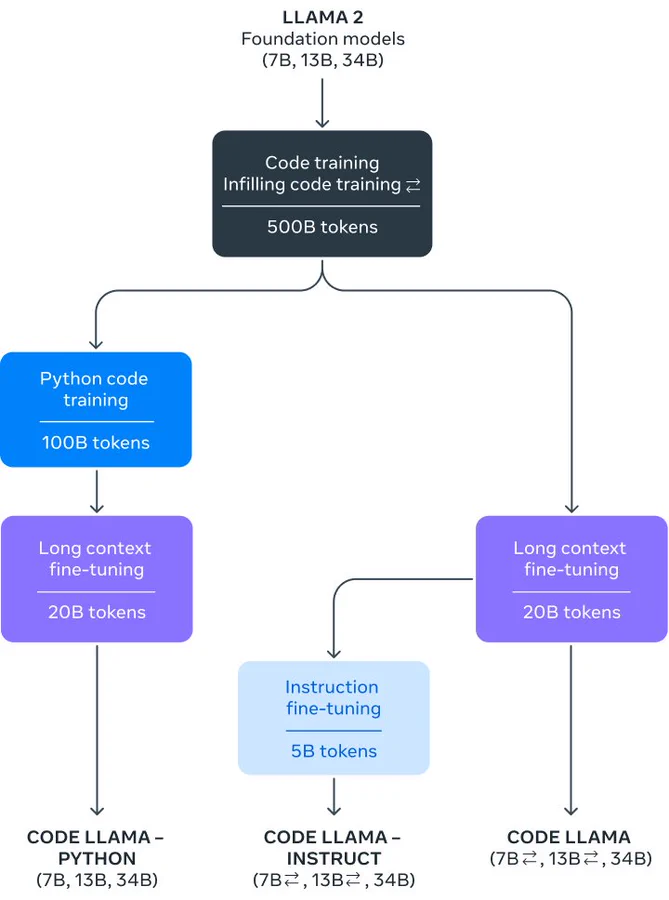
Code Llama is a code-specialized version of Llama 2 that has been further trained on code-specific datasets. It can generate code and natural language about code from both code and natural language prompts. It supports popular programming languages such as Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash. Code Llama can be used for code completion, code generation, and debugging. It is designed to help programmers write robust and well-documented software.
Code Llama models provide stable generations with up to 100,000 tokens of context. The models are trained on sequences of 16,000 tokens and show improvements on inputs with up to 100,000 tokens. Having longer input sequences unlocks new use cases for Code Llama, such as providing more context from a codebase to make the generations more relevant. It also helps in debugging scenarios in larger codebases, where staying on top of all code related to a concrete issue can be challenging for developers. When faced with debugging a large chunk of code, developers can pass the entire length of the code into the model.
Benchmark Testing Against Other AI Coding Tools
Code Llama’s benchmark performance is impressive compared to other models. It outperforms open-source, code-specific language models (LLMs) and even surpasses Llama 2. For example, Code Llama 34B achieved a score of 53.7% on the HumanEval benchmark and 56.2% on the Mostly Basic Python Programming (MBPP) benchmark. These scores are the highest among other state-of-the-art open solutions and are on par with ChatGPT.
The advantage of Code Llama lies in its enhanced coding capabilities. It is a code-specialized version of Llama 2, trained on code-specific datasets and sampled for longer. It can generate code and natural language about code, complete code, and assist in debugging. It supports popular programming languages like Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash.
Code Llama offers three different sizes with 7B, 13B, and 34B parameters, each trained with 500B tokens of code and code-related data. The smaller models (7B and 13B) have fill-in-the-middle (FIM) capability, enabling code completion out of the box. The 34B model provides the best results and superior coding assistance. However, the smaller models are faster and more suitable for low-latency tasks like real-time code completion.

In summary, Code Llama’s benchmark performance is excellent, surpassing other models in code-specific tasks. Its enhanced coding capabilities, support for multiple programming languages, and different model sizes make it a powerful tool for developers, improving efficiency and productivity in coding workflows.