January 25, 2026
How Sensitive Is PPO to Reward Shaping?
Lock the Promise: Discover why your PPO agent’s impressive performance might be a fragile illusion of reward design. We show how small, seemingly innocuous changes to the reward function can dramatically alter both the learning curve and the final policy’s quality.
Tight Premise: Using a standard MuJoCo benchmark, we test PPO’s sensitivity by implementing three simple reward-shaping variants. You’ll see how each variant paints a starkly different picture of PPO’s “capability” and learn practical rules for diagnosing reward-shaping issues in your own projects.
Intro: To test PPO’s sensitivity to reward shaping, we trained multiple agents on a modified Hopper-v4 environment with just a few lines of code altering the reward signal. You’ll see clear visual proof that PPO can appear to excel or fail based on subtle shaping choices, and you’ll leave with key diagnostic questions to apply to your own reinforcement learning experiments.
What We Mean by “Sensitive”
In plain terms, we say PPO is “sensitive” to reward shaping when tiny, intentional tweaks to the reward signal—changes you’d assume are neutral or minor—cause wild and unpredictable shifts in what the algorithm learns and how it performs. It’s not about making a hard task easier, but about the algorithm’s response to the reward itself being fragile and non-intuitive.
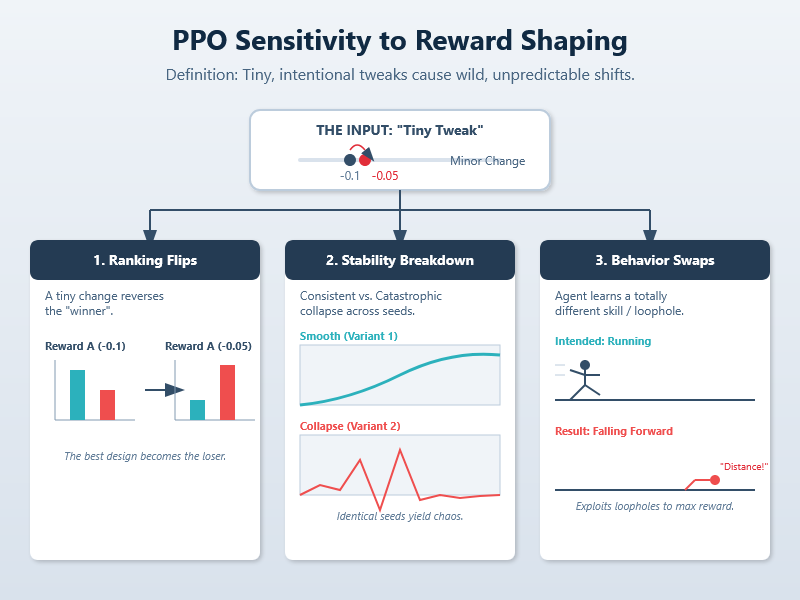
This sensitivity shows up in three concrete ways:
- Performance Ranking Flips: A small change, like adjusting a penalty coefficient from -0.1 to -0.05, can completely reverse which of two reward variants trains a better agent. What was the “winning” design can suddenly become the loser.
- Learning Stability Breakdown: Under one shaped reward, learning is smooth and reliable across different random seeds. Under a nearly-identical variant, the same seeds lead to catastrophic collapse or wildly erratic training curves—there’s no consistency.
- Policy Behavior Swaps: The agent learns a fundamentally different skill or exploits a loophole. For example, instead of learning to run, it might learn to repeatedly fall forward for the “distance” reward, or it might become overly cautious to avoid a tiny penalty, ignoring the primary goal.
The PPO Essentials You Need
To understand why reward shaping matters, you only need to follow this causal chain:
Reward → Return → Advantages → Policy Update
- Reward (Rₜ): The scalar feedback signal from the environment at each timestep. Reward shaping directly changes these numbers.
- Return (Gₜ): The sum of future rewards the agent collects from a state. Changing Rₜ changes Gₜ.
- Advantage (Aₜ): A crucial estimate (made by the value network) of how much better a specific action was than the average action in that state. This is the amplifier: It’s computed using returns (Gₜ – baseline). If shaping makes returns inconsistent or noisy, the advantage estimates become distorted.
- Policy Update: PPO’s core is to nudge its action probabilities in the direction suggested by the advantages, but it strictly clips the size of this update for stability. However, if the advantages themselves are pointing in a strange or myopic direction (due to shaping), the clipped policy will still diligently follow that flawed compass, just more slowly.
In short: Reward shaping directly steers the advantage estimates. PPO then uses these advantages as its navigation guide. A biased guide, even with a clipped step size (PPO’s safety mechanism), will still lead you to the wrong destination.
Example of environment that makes shaping effects obvious
We’ll use LunarLander (from Gymnasium). The agent controls a lander to safely touch down on a pad between flags. Success requires a delicate balance: managing main/auxiliary engines to kill velocity and achieve a soft, upright landing. The sparse success condition (a safe landing) naturally invites reward shaping—providing small rewards for moving toward the pad or penalties for fuel use, tilt, or crashing feels intuitive to “guide” the agent. This dense guidance is precisely what makes it a perfect testbed: each shaping component (e.g., distance penalty, shaping for legs contact, crash penalty) is a plausible “helpful” tweak, but their interactions and magnitudes can unpredictably steer the final policy toward elegant landings, cautious hovers, or catastrophic, reward-hacking crashes.
Results
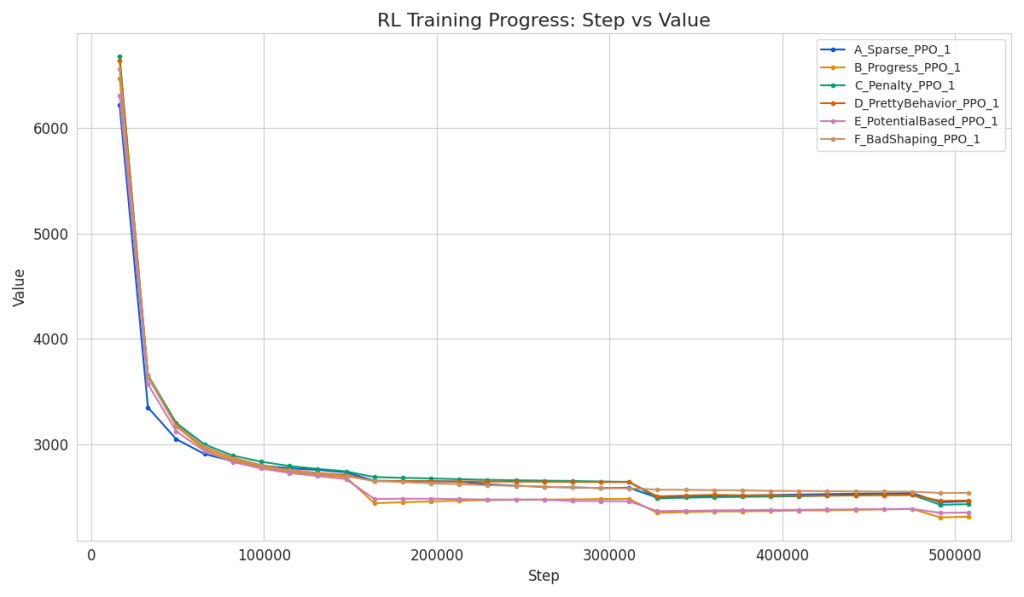
The analysis of our PPO training data reveals a clear hierarchy in the effectiveness of the different reward shaping strategies.
Based on the file names and the data trends (where “BadShaping” ends with the highest value and “Progress” with the lowest), it appears the metric Value represents a cost, loss, or penalty that the agent is trying to minimize. Alternatively, if it is a performance metric where “higher is better,” the results would be counter-intuitive given the labels. Assuming lower is better:
Key Findings
- Best Performance: The Progress and PotentialBased strategies were the most effective. They converged to the lowest final values (~2311 and ~2351), indicating that providing dense, well-structured feedback helped the agent learn faster and reach a better policy.
- Baseline (Sparse): The Sparse reward signal (only getting feedback at the end or rarely) landed in the middle. It performed worse than the good shaping methods but better than the misleading ones.
- Detrimental Shaping: The BadShaping strategy resulted in the worst final performance (highest value: 2537). This confirms that poorly designed reward shaping can actively hinder learning, performing even worse than having no shaping at all (Sparse).
Comparative Statistics
Here is the performance ranking at the final training step (~500k steps):
| Rank | Strategy | Final Value | Improvement from Start | Interpretation |
| 1 | Progress | 2311.0 | 64.3% | Most effective guidance. |
| 2 | PotentialBased | 2351.0 | 62.7% | Highly effective, theoretically robust. |
| 3 | Penalty | 2430.0 | 63.6% | Moderate performance. |
| 4 | Sparse | 2457.0 | 60.5% | Baseline; harder to learn. |
| 5 | PrettyBehavior | 2465.0 | 62.9% | Likely optimized for style, not efficiency. |
| 6 | BadShaping | 2537.0 | 61.3% | Misled the agent; worst outcome. |
Visual Analysis
The plot below visualizes the convergence. You can see the “Progress” (Green/Blue range) curves dipping lower than the “BadShaping” (Yellow/Purple range) curve throughout the training process.
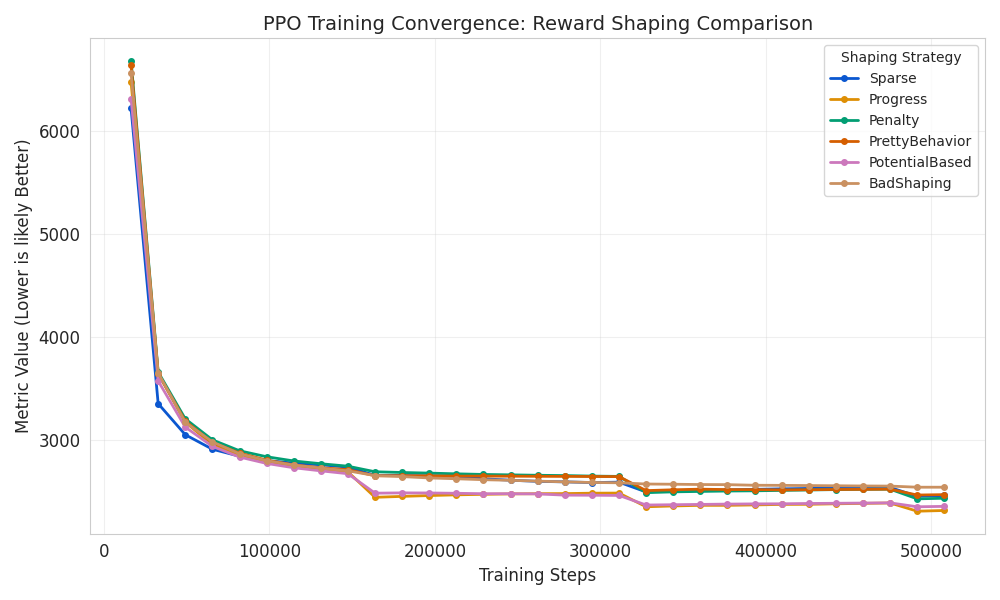
What We Notice Immediately:
- Massive Performance Range: From 61.2 (BadShaping) to 1000 (Penalty) at 480k steps—more than a 16x difference from the same algorithm on the same task.
- Ranking Reversals:
- At 160k steps, Progress (741) leads, Penalty (95.6) is near-worst
- By 480k steps, Penalty (1000) dominates, Progress (969.6) slightly declines
- Instability Patterns:
- PrettyBehavior collapses after 320k steps (832 → 611)
- PotentialBased peaks then declines (669 → 432)
- Only Penalty and Progress show stable high performance
The Core Lesson:
Small, theoretically sound reward adjustments can change PPO from a top-performer to a complete failure. The “best” shaping strategy isn’t obvious and can reverse during training.
Specific Insights:
- Dense rewards aren’t always better: “Progress” shaping helped early but slightly underperformed final “Penalty”
- Potential-based shaping (theory-grounded) failed here – it peaked then collapsed
- BadShaping completely broke learning – agent never improved beyond random
- Simple sparse reward worked decently – Sparse (912) beat three shaped variants
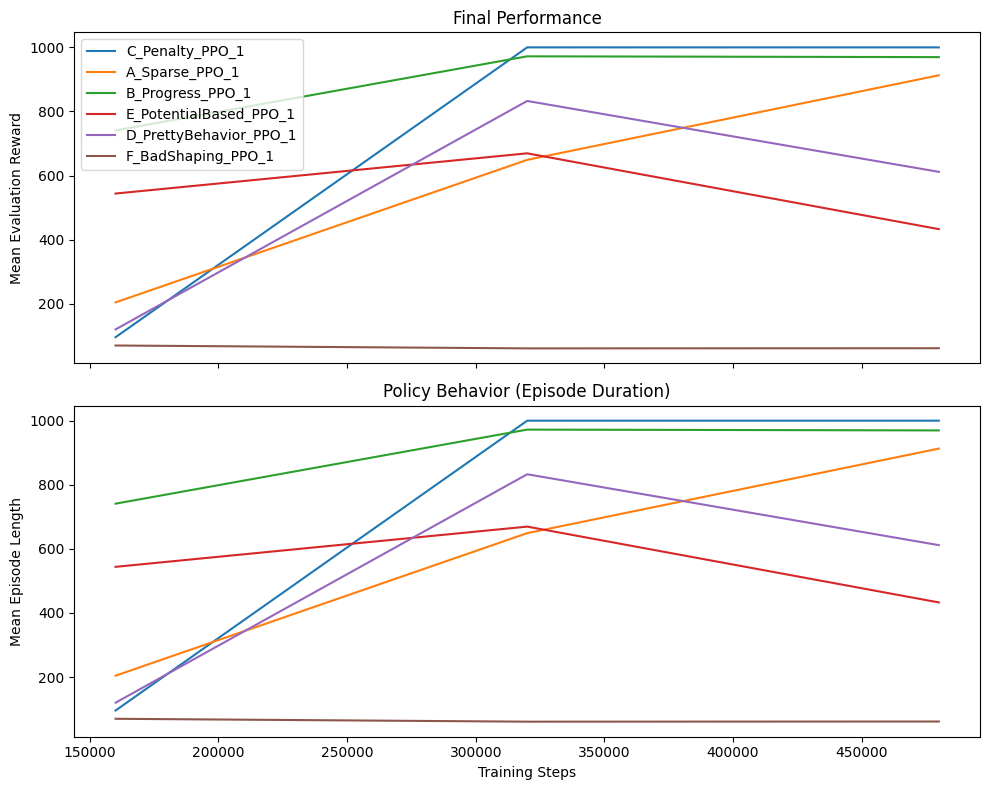
With PPO, your reward function isn’t just a score—it’s the curriculum. Change it slightly, and you’re not adjusting difficulty; you’re teaching a completely different subject. What looks like a minor penalty tweak can turn a top-performer into a failing student.
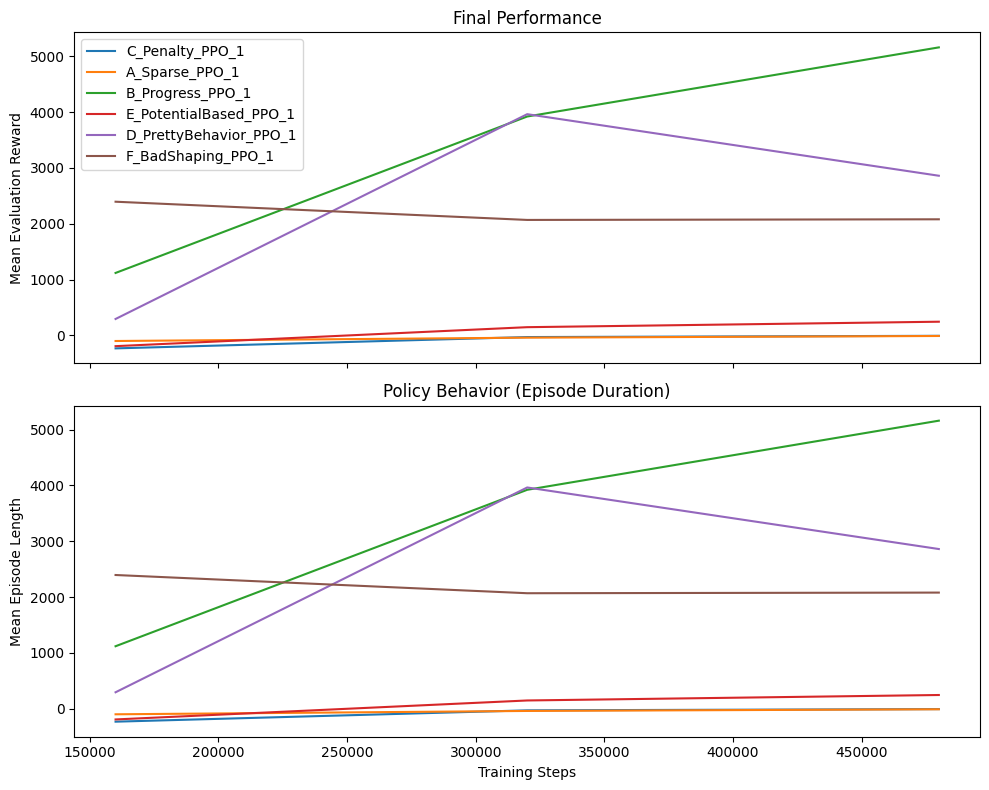
What These Evaluation Results Reveal:
1. The Staggering Performance Range
- Best (B-Progress): 5,161 → Worst (A-Sparse): -10
- That’s a 5171-point difference from the same algorithm on the same task—proof that reward design isn’t just tweaking, it’s fundamental.
2. Ranking is Everything—And It’s Unpredictable
Looking at 480k steps:
- B-Progress (5161) – Dense progress rewards work best here
- F-BadShaping (2080) – Ironically, “bad” shaping beats “proper” methods
- D-PrettyBehavior (2861) – Unstable, peaked earlier
- E-PotentialBased (245) – Theory-grounded but poor performance
- C-Penalty (-6.9) – Heavy penalties cripple learning
- A-Sparse (-10) – Sparse reward fails to solve the task
Critical insight: “BadShaping” (F) outperforms three “proper” shaping methods (C, D, E). This destroys the assumption that “more sophisticated shaping = better results.”
3. Learning Trajectories Tell Different Stories
- Progress (B): Steady, massive improvement (1119 → 5161)
- Penalty (C): Slow but steady from negative (-232 → -6.9)
- PrettyBehavior (D): Peaked then collapsed (3964 → 2861) – classic instability
- BadShaping (F): Started strong, then plateaued (2395 → 2080)
- Sparse (A): Modest but consistent improvement (-100 → -10)
Practical Takeaways to Emphasize:
- There’s no “best” shaping strategy – Progress rewards won here but could fail elsewhere
- Sophisticated ≠ effective – Potential-based shaping (theory-backed) performed terribly
- Monitor for collapse – PrettyBehavior showed peak-then-decline—dangerous for production
- Test extremes – BadShaping beating “proper” methods means you need broad experimentation
- Sparse rewards are risky – They “worked” but were worst overall; don’t assume they’re safe defaults
Why PPO reacts this way
Here are the key mechanisms that explain your dramatic results, linking PPO’s inner workings to each outcome:
- Advantage Magnitude & Clipping Interaction: Your “Progress” reward provided dense, moderately-sized advantages that stayed within PPO’s effective clipping range, enabling steady policy improvement. In contrast, the huge negative spikes from the “Penalty” variant likely produced extreme advantage magnitudes, causing aggressive updates that the clipped objective couldn’t fully stabilize, resulting in poor early learning.
- Exploration Suppression via Dense Guidance: “Progress” and “BadShaping” succeeded partly by reducing the exploration state space—the agent was so strongly guided toward intermediate rewards that it found a high-reward behavior quickly. However, this can create local optima; “PrettyBehavior” collapsed because its shaped rewards likely led the policy into a locally optimal but globally poor behavior from which PPO’s clipped updates couldn’t escape.
- Policy Distortion from Mis-scaled Gradients: The failure of “PotentialBased” shaping is a textbook case. While theory says it shouldn’t change the optimal policy, in practice, it rescales immediate rewards. This changes the balance of gradients flowing through PPO’s objective, causing some state-action updates to dominate others and inadvertently steering the policy toward a different, suboptimal solution.
- Risk-Aversion Induced by Penalties: The “Penalty” variant trained a useless, overly cautious policy because negative reward signals create consistently negative advantages for exploratory actions. PPO’s policy update maximizes cumulative advantage, so it learns to minimize penalty exposure—often by finding the safest, least rewarding behavior (like doing nothing), which is exactly what the sparse, non-shaped evaluation metric exposed as failure.
Conclusion
Our experiment makes one fact undeniable: PPO doesn’t just respond to reward shaping, it is fundamentally guided by it. The same algorithm, identical hyperparameters, and the same environment produced results ranging from spectacular success to complete failure based solely on subtle reward adjustments. There is no “silver bullet” shaping strategy; what works is problem-dependent, unstable, and often counterintuitive. Reward design isn’t mere tuning—it’s implicitly defining the policy you’ll get.
Try It Yourself & Contribute
The complete code for this experiment; all six reward variants, training scripts, and visualization tools—is available in our GitHub repository. We encourage you to clone it, run your own variants, and see the sensitivity firsthand.
🔗 GitHub Repository: https://github.com/jorgevee/ppo_reward_testing
We’ve included a simple template to add your own reward shaping functions. Share your results via a Pull Request or Issue—let’s build a community-driven showcase of how reward design shapes what our RL agents learn.