
July 12, 2025
Kimi K2: The Open Source Agentic AI Redefining the Frontier of Execution
Introduction: A Paradigm Shift from Thinking to Acting
The landscape of artificial intelligence has long been dominated by models that excel at thinking generating human-like text, answering questions, and engaging in nuanced conversation. In July 2025, Moonshot AI introduced a model built on a different premise: to act. Kimi K2, a new trillion parameter, open source large language model, represents a fundamental architectural and strategic divergence from its contemporaries. It is engineered from the ground up not merely for dialogue, but for autonomous execution, tool use, and complex workflow orchestration.1
Kimi K2 is more than a powerful new model; it is a meticulously engineered system that challenges the dominance of closed, conversational AI. Through its novel architecture, state-of-the-art performance in practical domains, and disruptive open source, low cost strategy, Kimi K2 is democratizing the development of sophisticated AI agents and forcing a market-wide re-evaluation of what a frontier model should be.
This report provides an exhaustive deconstruction of Kimi K2, examining its technical underpinnings, benchmark performance against industry leaders, and practical implications for developers and researchers. At its core, the model is defined by several key characteristics:
- A 1 trillion-parameter Mixture-of-Experts (MoE) architecture, which delivers immense scale while maintaining computational efficiency by activating only 32 billion parameters per inference.1
- A design philosophy centered on “agentic intelligence,” enabling the model to autonomously use tools, execute multi-step tasks, and orchestrate complex workflows with minimal human oversight.1
- An open weight distribution, allowing developers and researchers to download, fine tune, and deploy the model locally, fostering a new wave of innovation outside the confines of proprietary APIs.6
- Its origin from MoonshotAI, a Chinese company, underscores the decentralization of frontier AI development and intensifies global competition, proving that state-of-the-art performance is no longer exclusive to Silicon Valley.1
The arrival of Kimi K2 is not just a technological milestone; it is a strategic maneuver with significant market and geopolitical implications. By releasing a model of this caliber as open source, MoonshotAI is not only attempting to reclaim market share in a competitive domestic landscape but is also building a global developer ecosystem around its technology.9 This approach creates a powerful competitive moat based on community adoption and network effects, directly challenging the closed IP business models of incumbents like OpenAI and Anthropic. Kimi K2 is a declaration that the future of AI may be both powerful and open.
Under the Hood: The Architecture of an Execution-First Model
The remarkable capabilities of Kimi K2 are not accidental; they are the result of deliberate and innovative architectural choices designed to solve the fundamental challenges of scaling AI models to unprecedented sizes. This section deconstructs the key technical components that enable Kimi K2’s unique blend of power and efficiency.
The Mixture-of-Experts (MoE) Advantage: Scale with Efficiency
At the heart of Kimi K2 lies a Mixture-of-Experts (MoE) architecture, a sophisticated design that allows for massive parameter counts without a proportional increase in computational cost during inference.1 Conceptually, an MoE model operates like a team of specialized consultants rather than a single generalist. Instead of activating its entire neural network for every task, it intelligently routes the task to the most relevant experts.
Specifically, Kimi K2 contains a total of 1 trillion parameters distributed across 384 distinct “experts.” When processing an input token, a lightweight routing network selects the most appropriate 8 experts to handle the computation. These are supplemented by one shared expert that provides global context, ensuring coherence across the model’s outputs.1 This means that for any given forward pass, only
32 billion parameters are active.
The significance of this sparse activation cannot be overstated. It allows Kimi K2 to possess the vast knowledge and nuanced representational capacity of a trillion parameter model while incurring the inference cost and latency closer to that of a much smaller 32-billion parameter dense model.4 This architectural trade off is the key to making a model of this scale practical and economically viable for real-world deployment.
The MuonClip Optimizer: The Key to Stable Trillion Parameter Training
One of the most significant, yet often overlooked, challenges in developing frontier AI models is training instability. As models grow larger, they become prone to numerical issues, particularly “exploding attention logits,” where values within the attention mechanism spiral out of control, causing the entire training run to fail. This instability has been described as a “hidden tax” on LLM development, forcing labs to restart expensive, months long training runs and accept suboptimal performance to avoid crashes.4
Moonshot AI has engineered a direct solution to this problem with its custom MuonClip optimizer. Derived from the previously developed Muon optimizer, MuonClip introduces a novel technique called qk-clipping. This method directly rescales the weight matrices of the query (Q) and key (K) projections after each optimizer update, effectively constraining the scale of the attention logits at their source and preventing them from “blowing up”.1
The effectiveness of this approach is profound. Moonshot AI reported a completely stable pre-training run on an unprecedented 15.5 trillion tokens with “zero training instability” or loss spikes.1 This engineering achievement is arguably more significant than the model’s parameter count. It demonstrates a mastery over the scaling process, giving Moonshot AI a crucial advantage in developing future models more reliably and efficiently than competitors still grappling with instability. This stability enables more predictable scaling laws, allowing for more strategic long-term R&D planning and a clearer path toward more advanced AI systems.
Data, Context, and Architectural Specifics
Kimi K2’s robust capabilities are built upon a massive foundation of data and a generous context window, which are critical for its performance in complex, real world tasks.
- Training Data: The model was pre-trained on a colossal 15.5 trillion token dataset, curated from a diverse range of multilingual and multimodal sources. This vast and varied dataset provides Kimi K2 with strong generalization capabilities, enabling it to reason and use tools effectively across numerous domains.1
- Context Window: Kimi K2 features a 128,000 token context window.3 The context window functions as the model’s short-term memory, defining how much information it can hold and process at once. A large context window is essential for agentic workflows, allowing the model to analyze entire code repositories, ingest and summarize lengthy legal or financial documents, or maintain coherence over extended, multi-step interactions without losing critical details.19
For a complete technical overview, the model’s architectural specifications are consolidated below.
Table 1: Kimi K2 Technical Specifications at a Glance
| Specification | Detail | Source(s) |
| Architecture | Mixture-of-Experts (MoE) | 1 |
| Total Parameters | 1 Trillion | 1 |
| Active Parameters | 32 Billion | 1 |
| Number of Layers | 61 | 11 |
| Number of Experts | 384 | 1 |
| Selected Experts / Token | 8 (+1 shared) | 1 |
| Context Length | 128,000 tokens | 3 |
| Optimizer | MuonClip | 1 |
| Training Tokens | 15.5 Trillion | 1 |
| Attention Heads | 64 | 1 |
| Vocabulary Size | 160,000 | 15 |
Performance Analysis: A New State-of-the-Art in Practical Execution
A model’s true measure lies not in its parameter count but in its performance on meaningful tasks. Kimi K2 has been rigorously evaluated against a suite of industry standard benchmarks, where it consistently demonstrates state-of-the-art capabilities, particularly in domains that reflect real world, practical challenges. Its performance profile reveals a clear focus on execution oriented intelligence.
The Rise of the Agentic Coder: Dominance on Real World Benchmarks
Modern coding benchmarks have evolved beyond testing a model’s ability to write isolated functions. They now measure comprehensive software engineering competence.
- SWE-bench Explained: The Software Engineering Benchmark (SWE-bench) is a demanding evaluation that tests a model’s ability to resolve real GitHub issues from popular open source projects. It requires the model to understand complex, existing codebases, diagnose subtle bugs, and write functional code patches that pass the project’s original test suite. It is a direct measure of engineering skill, not just coding fluency.22
- Kimi K2’s Performance: On the agentic version of SWE-bench Verified, Kimi K2 Instruct achieves a score of 65.8% on a single attempt and 71.6% with multiple attempts. This places it well ahead of GPT-4.1 (54.6%) and in the same elite tier as Claude 4 Sonnet and Opus (which score ~72.5%).1
- LiveCodeBench & OJBench Explained: LiveCodeBench simulates the interactive, conversational nature of a pair programming session or a live coding interview, evaluating a model’s ability to adapt to feedback and revise its code. OJBench (Online Judge Benchmark) tests raw algorithmic skill and precision under the strict constraints of competitive programming platforms.22
- Kimi K2’s Performance: Kimi K2 decisively outperforms its main proprietary rivals on these demanding coding tests, scoring 53.7% on LiveCodeBench and 27.1% on OJBench, surpassing both GPT-4.1 and Claude 4 Opus.5
Beyond Code: Prowess in Mathematical and Scientific Reasoning
Kimi K2’s capabilities extend into the complex domain of STEM, where it demonstrates a capacity for deep, multi-step symbolic reasoning that has historically been a challenge for LLMs.
- AIME, MATH-500, & GPQA-Diamond Explained: These are not simple knowledge recall tests. They represent the pinnacle of reasoning benchmarks. AIME (American Invitational Mathematics Examination) features problems from the Math Olympiad circuit. MATH-500 contains graduate level mathematical problems. GPQA-Diamond (Graduate-Level Physics Questions) is composed of questions from PhD level physics exams that require a deep understanding of theoretical concepts.22
- Kimi K2’s Performance: The model establishes itself as a leader in this category. It achieves a remarkable 97.4% on MATH-500, significantly higher than GPT-4.1’s 92.4%. It also scores 49.5% on the difficult AIME 2025 benchmark and 75.1% on GPQA-Diamond, leading the charts among models that do not rely on extended “thinking time” at inference.5
The Agent in Action: Native Tool Use and Workflow Orchestration
The core of Kimi K2’s design philosophy is its agentic capability the ability to act. This is evaluated by benchmarks that test its proficiency in using external tools to accomplish goals.
- Tau2 Bench & AceBench Explained: These benchmarks assess a model’s capacity for multi-hop reasoning and planning. They require the model to interact with external tools such as APIs, databases, or shell commands to solve complex, multi-step problems, thereby measuring its ability to orchestrate a workflow.22
- Kimi K2’s Performance: The model’s specialized training shines here. It achieves a weighted average of 66.1% on Tau2 Bench and an impressive 80.1% on AceBench (English), confirming its deeply integrated tool use capabilities. Demonstrations from Moonshot AI show the model autonomously orchestrating over 17 distinct tool calls in a single, seamless workflow to complete a user request.1
This outstanding performance across practical benchmarks points to a significant conclusion. Kimi K2 is described as a “reflex-grade model without long thinking”.15 While this might sound like a limitation, the data suggests it is a feature. The model outperforms competitors that rely on “thinking-time” hacks, where they explicitly generate long chains of thought at inference time.4 Kimi K2’s specialized agentic training appears to have “compiled” this reasoning capability directly into its neural weights. This allows for faster, more efficient, and more direct execution without sacrificing performance on complex tasks. It challenges the prevailing industry assumption that more explicit “thinking” at inference is the only path to greater intelligence, suggesting a new direction for LLM development focused on embedding execution capability into the model itself.
Table 2: Kimi K2 vs. The Incumbents; Key Benchmark Showdown
| Benchmark | Metric | Kimi K2-Instruct | GPT-4.1 | Claude 4 Sonnet | Claude 4 Opus | DeepSeek-V3 |
| SWE-bench Verified | Agentic, Single Attempt (Acc) | 65.8% | 54.6% | 72.7%* | 72.5%* | 38.8% |
| LiveCodeBench v6 | Pass@1 | 53.7% | 44.7% | 48.5% | 47.4% | 46.9% |
| MATH-500 | Accuracy | 97.4% | 92.4% | 94.0% | 94.4% | 94.0%* |
| AIME 2025 | Avg@64 | 49.5% | 37.0% | 33.1%* | 33.9%* | 46.7% |
| GPQA-Diamond | Avg@8 | 75.1% | 66.3% | 70.0%* | 74.9%* | 68.4%* |
| MMLU | Exact Match (5-shot) | 89.5% | 90.4% | 91.5% | 92.9% | 89.4% |
| Tau2-Bench | Weighted Avg (Retail) | 70.6% | 74.8% | 75.0% | 81.8% | 69.1% |
Note: Asterisk () indicates scores may have different evaluation parameters (e.g., extended thinking time, different model versions). Data compiled from.1*
The Competitive Landscape: How Kimi K2 Stacks Up
Kimi K2 enters a crowded field of powerful AI models, but its unique combination of performance, openness, and cost positions it as a significant disruptor. A strategic analysis reveals a clear value proposition against both proprietary and open source competitors.
Kimi K2 vs. OpenAI’s GPT Series (GPT-4.1, GPT-4o)
While OpenAI’s GPT models, particularly later versions like GPT-4o, often lead in broad knowledge benchmarks such as MMLU, Kimi K2 carves out a distinct advantage in practical, execution oriented domains.1 As shown in the benchmark analysis, Kimi K2 consistently outperforms GPT-4.1 in challenging coding and mathematics evaluations like LiveCodeBench, OJBench, and MATH-500.5 The fundamental difference lies in their design philosophy. GPT models are powerful generalists optimized for creative and conversational tasks. Kimi K2, by contrast, is a specialist engineered for agentic workflows. For developers building autonomous systems that need to write code, use tools, and execute complex sequences, Kimi K2 presents a more capable and purpose built foundation.
Kimi K2 vs. Anthropic’s Claude Series (Claude 4 Sonnet/Opus)
The comparison with Anthropic’s Claude family highlights a battle of architectural philosophies. Claude models are renowned for their large context windows and strong reasoning abilities, often achieved by using “extended thinking” time at inference, where the model generates internal monologues to reason through a problem.26 Kimi K2 achieves comparable or superior performance on many of these same reasoning and coding benchmarks
without this time consuming deliberation, making it inherently faster and more efficient.4 This “reflex grade” performance, combined with its fully open source nature and dramatically lower API costs, presents a formidable challenge to Claude’s premium, closed source business model.1
Kimi K2 vs. Open Source Giants (Llama 3, DeepSeek)
Within the open source ecosystem, Kimi K2 establishes a new state-of-the-art. It clearly outperforms its contemporary, DeepSeek-V3, on key agentic coding benchmarks.5 The comparison with Meta’s Llama 3 family is also instructive. Llama 3 models are powerful “dense” models, meaning all their parameters are activated for every inference. Kimi K2’s MoE architecture provides a more efficient path to scaling. It allows Kimi K2 to reach a trillion parameter scale while keeping inference requirements manageable, a critical advantage for organizations seeking to deploy or fine-tune large models on premise without cost prohibitive hardware.12
To visualize these competitive dynamics, the following charts provide a clear, data driven comparison.
Visualization 1: Competitive Benchmark Performance (Bar Chart)
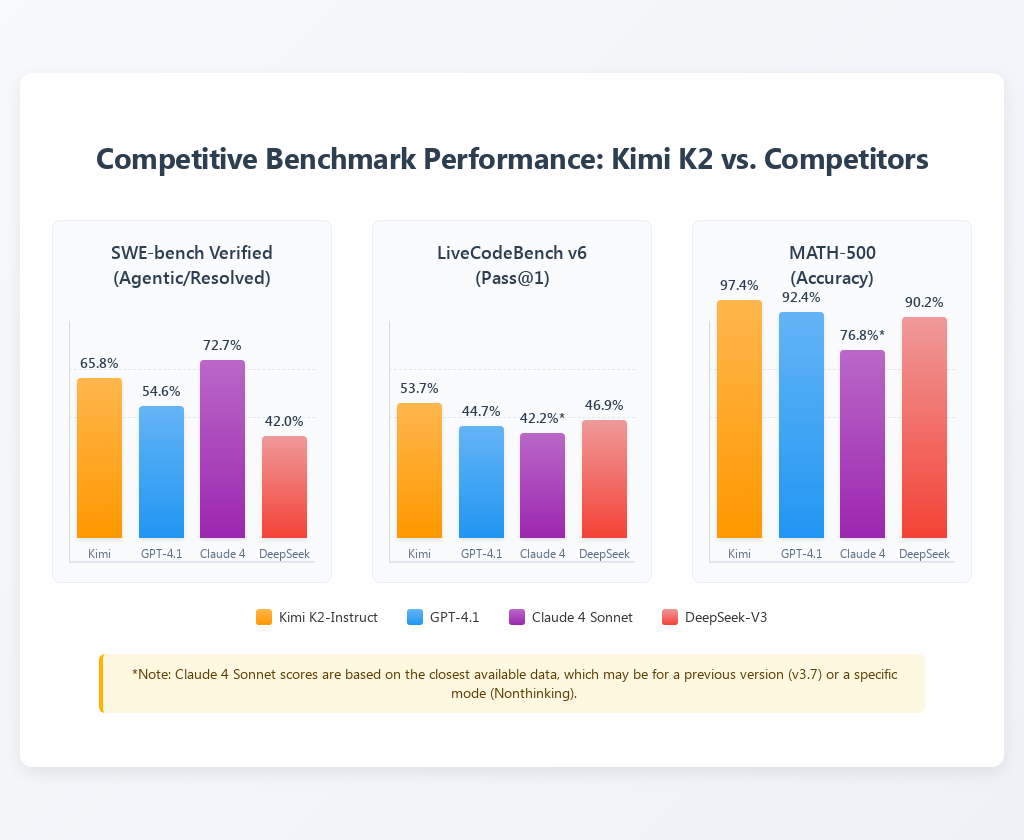
A bar chart would offer a direct visual comparison of Kimi K2 against its key competitors on the most demanding practical benchmarks.
- Chart Description: This chart would display the performance scores of Kimi K2-Instruct, GPT-4.1, Claude 4 Sonnet, and DeepSeek-V3 across three critical benchmarks: SWE-bench Verified (Agentic), LiveCodeBench v6 (Pass@1), and MATH-500 (Accuracy).
- Expected Outcome: The visualization would clearly show Kimi K2 leading or being highly competitive in all three categories, reinforcing its strength in real world coding and advanced reasoning tasks.
Visualization 2: Multi-Dimensional Capability Profile (Radar Chart)
A radar chart provides a holistic view of each model’s strengths and weaknesses across multiple dimensions, moving beyond single-score comparisons.
- Chart Description: This chart would plot the relative capabilities of Kimi K2, GPT-4o, and Claude 4 Opus across five strategic axes: (1) Agentic Coding, (2) Math & STEM Reasoning, (3) Tool Use & Orchestration, (4) General Knowledge (MMLU), and (5) Cost Effectiveness (an inverse measure of API pricing).
- Expected Outcome: Kimi K2’s profile would exhibit strong spikes in Agentic Coding, Math & STEM, and Tool Use, along with an exceptionally large spike for Cost-Effectiveness. In contrast, models like Claude 4 Opus might show a higher spike in General Knowledge but would be significantly lower on the cost axis, visually articulating the different value propositions.
A Developer’s Guide to Harnessing Kimi K2
Moonshot AI has made Kimi K2 remarkably accessible, providing multiple pathways for developers, researchers, and enterprises to integrate its capabilities. This section serves as a practical guide to getting started with the model.
Choosing Your Variant: Kimi-K2-Base vs. Kimi-K2-Instruct
Kimi K2 is released in two distinct variants, each tailored to different use cases 1:
- Kimi-K2-Base: This is the raw, foundational pre-trained model. It is the ideal starting point for research institutions and enterprises with the resources and expertise to perform custom fine-tuning. By training Kimi-K2-Base on proprietary datasets (e.g., internal codebases, legal documents, or financial data), organizations can create highly specialized agents optimized for their specific operational needs.
- Kimi-K2-Instruct: This is the post-trained, instruction-following version of the model. It has been optimized for general purpose chat and agentic tasks, making it suitable for immediate, “drop-in” use. As a “reflex-grade” model, it is designed for fast, low-latency interactions and provides powerful, out-of-the-box performance for building responsive AI assistants and applications.
Access and Integration: Getting Started with Kimi K2
Developers can access Kimi K2 through several flexible channels:
- Official API: Moonshot AI provides a robust API on its official platform (
platform.moonshot.ai). The API is designed for ease of use and is compatible with the popular OpenAI and Anthropic formats, which significantly lowers the barrier to entry for developers looking to migrate existing applications or experiment with Kimi K2.6 A simple API call using a standard library like OpenAI’s Python client can integrate Kimi K2 with just a few lines of code. - Hugging Face: True to its open source commitment, Moonshot AI has made the model weights for both Kimi-K2-Base and Kimi-K2-Instruct available on the Hugging Face Hub. This allows developers to download the model for local deployment and use it with popular, high-performance inference engines such as vLLM, SGLang, and TensorRT-LLM.6
- Third Party Providers: For developers who prefer a managed environment, Kimi K2 is also accessible through third party API providers like OpenRouter. These platforms often normalize API requests across hundreds of models, making it simple to switch between different AIs for testing and production.2
The Economics of Disruption: Pricing and Cost Effectiveness
Perhaps the most disruptive aspect of Kimi K2’s launch is its aggressive pricing strategy, which fundamentally alters the economic calculation for deploying frontier AI. The API for Kimi K2-Instruct is priced at approximately $0.60 per million input tokens and $2.50 per million output tokens (for a cache miss).5
This pricing is a fraction of the cost of its proprietary competitors. As illustrated in the table below, Kimi K2 is roughly 5 times cheaper than comparable models from Anthropic and Google, while offering equivalent or superior performance on many key benchmarks.1 This combination of elite performance and low cost makes sophisticated AI accessible to a much broader range of developers, startups, and enterprises, fueling a new wave of innovation.
Table 3: API Pricing – Kimi K2’s Economic Disruption
| Model | Price per 1M Input Tokens | Price per 1M Output Tokens |
| Kimi K2-Instruct | $0.60 | $2.50 |
| Claude 4 Sonnet | $3.00 | $15.00 |
| Gemini 2.5 Pro | $2.50 | $15.00 |
| GPT-4o | ~$3.00 – $5.00 (Blended) | ~$9.00 – $15.00 (Blended) |
Note: Prices are approximate and subject to change. GPT-4o pricing is blended based on various providers.
Deployment and Hardware: The Reality of Running a Trillion-Parameter Model
While the open weight nature of Kimi K2 allows for local deployment, it is crucial for developers to understand the significant hardware requirements. Running a model of this scale is a serious engineering undertaking.
- Production-Grade Hardware: For production use or on premise hosting, Kimi K2 requires a powerful GPU cluster, likely consisting of multiple NVIDIA B200 GPUs or a multi-node setup on NVIDIA’s Hopper architecture.25
- High-End Consumer/Prosumer Setups: It is theoretically possible to run a quantized version of the model on non enterprise hardware, but with major caveats. One report suggests a 4-bit quantized version could run on a system with two Apple M3 Ultra machines, each equipped with 512 GB of unified RAM.25 A standard
Q4_K_Mquantization of the model results in a file size of 621 GB, far exceeding the VRAM of any consumer-grade GPU.7 - The Performance Trade-Off: For those with substantial system RAM, it is possible to stream the model weights from memory or an SSD. However, this method results in extremely slow inference speeds, on the order of just 1 token per second on a machine with 64 GB of RAM.12
The clear takeaway is that while local deployment offers maximum control and privacy, it is currently only feasible for well resourced organizations. For the vast majority of developers and businesses, the most practical and cost effective way to leverage Kimi K2’s power will be through its highly affordable API.
Visualization 3: Cost vs. Performance Analysis (Scatter Plot)
A scatter plot provides the most compelling visual argument for Kimi K2’s market disrupting value proposition.
- Chart Description: This visualization would plot leading AI models on a 2D graph. The Y-axis would represent a composite performance score (e.g., an average of SWE-bench and MATH-500 scores), while the X-axis would represent the blended API cost per million tokens.
- Expected Outcome: Kimi K2 would appear as a dramatic outlier in the top-left quadrant of the chart, signifying both high performance and low cost. In contrast, proprietary models like GPT-4o and Claude 4 Opus would be clustered in the top-right quadrant (high performance, high cost), visually cementing Kimi K2’s position as the new leader in cost effective, frontier level AI.
The Future is Agentic: Strategic Implications and Conclusion
The release of MoonshotAI’s Kimi K2 is more than just another entry on the LLM leaderboard; it is an inflection point that signals a fundamental shift in the trajectory of artificial intelligence development. By successfully engineering a trillion parameter model optimized for action and releasing it to the world as an open source tool, Moonshot AI has not only redefined the performance frontier but has also challenged the strategic foundations of the AI industry.
Kimi K2 stands as a vanguard of the transition from “thinking” AI to “acting” AI. For years, the primary measure of a model’s intelligence was its ability to converse and reason in abstract terms. Kimi K2 demonstrates that the next great leap lies in execution the ability to autonomously decompose problems, orchestrate tools, and produce tangible outputs like functional code, data visualizations, and completed workflows.1 This shift has profound implications, promising to transform software development, scientific research, and business automation by empowering AI to move from being a passive assistant to an active collaborator.
Furthermore, Kimi K2’s arrival marks a major victory for the open source movement. It proves definitively that open weight models can compete with, and in critical domains, surpass the most advanced proprietary systems.2 This democratization of power threatens the moats of incumbent players built on closed IP and empowers a global community of developers to build, customize, and innovate at an unprecedented pace. The aggressive, low cost API further accelerates this trend, making frontier capabilities accessible to all.
Of course, the model is not without its limitations. As a “reflex-grade” system, it can struggle with tasks that require long chains of fuzzy, ambiguous reasoning or that are based on poorly defined instructions.4 Its current iteration also lacks multimodal vision capabilities, a feature that is becoming standard in other frontier models.4 However, these limitations are likely temporary. The potential arrival of a future “thinking” version of Kimi K2, built upon the same stable and efficient training foundation, could further disrupt the competitive landscape.8
In conclusion, Kimi K2 is a catalyst. It is a blueprint for a future where AI systems do more than generate text; they build, act, and solve problems autonomously. By combining immense scale with groundbreaking training stability, state-of-the-art agentic performance, and a disruptive open source strategy, MoonshotAI has thrown down the gauntlet. The question facing the industry is no longer if open source models can reach the frontier, but how quickly the world will adapt to a new reality where the most powerful tools are available to everyone. The age of the autonomous agent is here, and it is open source.