
September 26, 2023
Falcon 180B Takes Flight: Exploring the Capabilities
The field of natural language processing is advancing at a rapid pace, empowered by the development of ever-larger and more capable AI models. The latest entrant aiming to push boundaries in this space is Falcon 180B – a newly released open-source language model boasting 180 billion parameters.
With its vast scale and cutting-edge design, Falcon 180B represents an exciting milestone in AI’s quest to reach human levels of language proficiency. We’ll take a closer look at this powerful new system, examining its origins, capabilities, and performance benchmarks.
Developed by Innovation Institute (TII) in Abu Dhab, Falcon 180B demonstrates remarkable prowess on natural language tasks. It currently ranks at the top of the Hugging Face Leaderboard for open-source large language models, even surpassing models from leading AI labs like Meta and Google in certain tests.
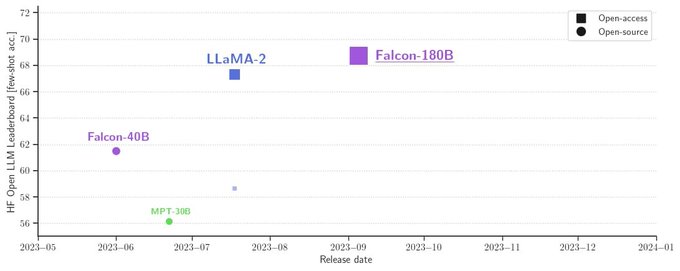
Under the hood, Falcon 180B implements a novel training methodology focused on Constitutional AI principles like safety, honesty and truth-seeking. This rigorous approach has yielded a model with state-of-the-art natural language understanding, while also aligning its goals and incentives with human values.
As AI continues its relentless march forward, models like Falcon 180B underscore the rapid progress being made. In this article, we’ll analyze its strengths, benchmark its abilities, and assess its implications for the future of language AI. The flight of Falcon 180B is just beginning – let’s explore where its wings may take us next.
Model Specifications
The recently released Falcon-180B is a language model that has 180 billion parameters and is trained on 3.5 trillion tokens. It is a causal decoder-only model trained on a causal language modeling task, which means it predicts the next token. Falcon-180B is the most powerful open LLM and ranks first on the Hugging Face leaderboard for open access LLMs. It is on par with GPT-4 and Google’s PaLM 2
Setup & Performance
To swiftly run inference with Falcon-180B, you will need at least 400GB of memory. The hardware requirements for training Falcon-180B are QLoRA 160GB 2x A100 80GB, and for inference, GPTQ/int4 320GB 8x A100 40GB1. The size of Falcon-180B is 102GB for falcon-180B-q4_K_M.gguf and 138GB for falcon-180B-q6_K.gguf. To put its size into perspective, Falcon-180B consists of parameters that are 2.5 times larger than Meta’s LLaMA 2 model.
Data Use
The data in the table you sent shows the sources of data used to train the Falcon 180B model. The table is titled “Data source” and has 6 rows and 3 columns. The first column, titled “RefinedWeb”, lists the different sources of data used to train the model. The second column, titled “Fraction”, shows the percentage of the total training data that each source represents. The third column, titled “Tokens”, shows the number of tokens from each source used to train the model. According to the table, 75% of the training data for Falcon 180B comes from a massive web crawl in English, representing 750 billion tokens. 7% of the training data comes from a European crawl, representing 70 billion tokens. 6% of the training data comes from ebooks, representing 60 billion tokens. 5% of the training data comes from conversations on platforms like Reddit, StackOverflow, and HackerNews, representing 50 billion tokens. Another 5% of the training data comes from code, representing 50 billion tokens. Finally, 2% of the training data comes from technical sources like arXiv, PubMed, and USPTO, representing 20 billion tokens.
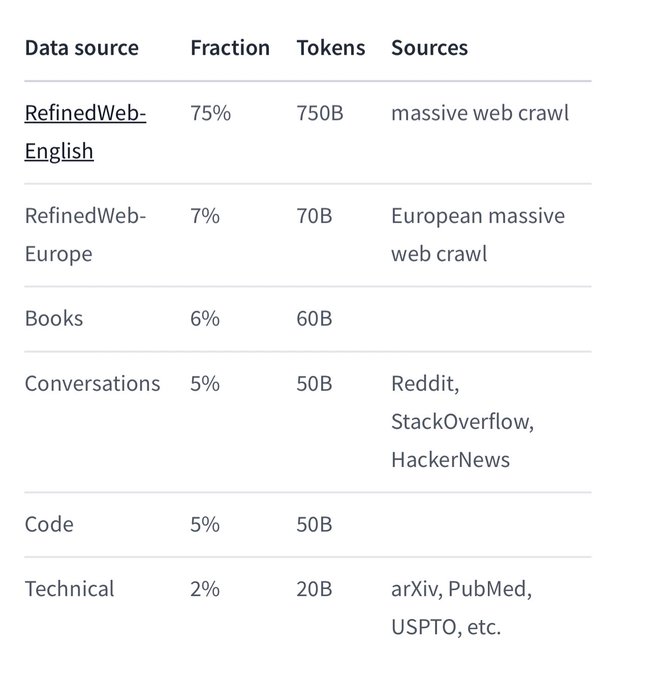
However, there is a concern about the limited representation of code in the training mix, as it only comprises 5%. Code is seen as highly valuable for boosting reasoning, mastering tool use, and empowering AI agents. In fact, GPT-3.5 is finetuned from a Codex base. Without sufficient coding benchmark numbers and considering the limited code pretraining, it is assumed that the model may not perform well in coding-related tasks. Therefore, claims of being “better than GPT-3.5” or approaching GPT-4 may not be justified without incorporating coding as an integral part of the pretraining recipe, rather than an afterthought in finetuning.
Not only that but, it is suggested that it is time to explore the use of Mixture of Expert (MoE) for models with a capacity of 30B+. While there have been MoE LLM models of less than 10B, it is essential to scale up significantly in order to advance the field.
Testing
To evaluate the performance of the model, we conducted testing by providing it with a straightforward LeetCode question, specifically the task of inverting a binary tree in Java. This is the result

Commercial Use
Here are the key points of the Falcon 180B license:
- Grants a royalty-free, worldwide, non-exclusive copyright and patent license to use, reproduce, distribute, and create derivative works of Falcon 180B (Sections 2 and 3)
- Requires distribution agreements for the model to incorporate enforceable Acceptable Use Policy and hosting restrictions (Section 4)
- Requires compliance with the Acceptable Use Policy, which may be updated by TII (Section 5)
- Requires public statements about derivative works to credit TII and Falcon 180B (Section 6)
- Contributions are under the terms of the license, unless stated otherwise (Section 7)
- Separate license required for “Hosting Use” like offering Falcon 180B through an API (Section 9)
- Provides the model on an “as is” basis, disclaiming warranties (Section 10)
- Limits liability of contributors (Section 11)
- Allows offering warranties/liability only on own behalf, not other contributors (Section 12)
In summary, it enables broad use of Falcon 180B but with restrictions like the Acceptable Use Policy, attribution, and no hosting without permission, while limiting contributor liability. All in all Falcon 180B does not appear to be open source.
Impact
The release of Falcon 180B represents an exciting milestone in the development of large language models. While not open source, its impressive capabilities highlight the rapid progress in AI. However, as adoption grows, it will be important to ensure these models are used responsibly and their benefits shared as widely as possible.
More openness and contribution from the AI community would be ideal to improve Falcon 180B. But the proprietary nature of the model and its specialized computational requirements currently limit participation. Running the 180 billion parameter model requires high-end GPUs, making consumer access difficult. And as we experienced, Falcon 180B has limitations in areas like coding, so open development could help strengthen its skills.
I hope the popularity of models like Falcon 180B accelerates work on optimized deployment. It’s disappointing quantized inference on CPUs isn’t more feasible yet. Supporting reduced precision and int8 or 4 bit quantization on CPUs would make these large models far more accessible. Theoretically, with a powerful CPU and enough RAM, Falcon 180B could already run acceptably for some applications. But full open source CPU support for ultra-low precision would be a gamechanger.
It’s unclear why quantized CPU inference receives so little focus compared to GPUs. There don’t appear to be fundamental technical barriers. And affordable, high-core CPUs can match GPU pricing. Unlocking fast int8 and lower quantization on CPUs would enable more participatory AI development. As large language models continue advancing, we need quantization and optimizations that keep pace so more users can benefit from these breakthroughs.