May 12, 2025
Using BM25 to Supercharge AI Agents
In the rapidly evolving world of AI agents, one challenge persists: how can we make them smarter, faster, and more context-aware—especially when navigating vast collections of unstructured text? That’s where BM25, a powerful sparse retrieval algorithm from the world of traditional information retrieval, comes into play. While vector embeddings dominate modern NLP pipelines, BM25 still holds a critical edge in certain contexts—offering precise keyword-based relevance scoring that can complement or even outperform dense retrieval in specific scenarios. Indeed, the foundational principles of BM25 are so effective that research suggests even advanced neural ranking models implicitly learn and re-implement semantic variants of its core logic. We’ll explore how integrating BM25s with LangGraph, a framework for building multi-step, stateful AI agents, can dramatically enhance performance, especially in sophisticated Agentic RAG (Retrieval-Augmented Generation) systems. From smarter document search to more effective memory recall, combining classical IR techniques with modern AI workflows unlocks a new level of capability.
Understanding BM25: The Fundamentals
BM25 (Best Matching 25) stands as one of the most successful and enduring algorithms in information retrieval. Developed as an evolution of the probabilistic relevance framework by Stephen Robertson and others in the 1970s and 1980s, it has become the default ranking algorithm for many search engines, including Elasticsearch and Solr.
At its core, BM25 is a bag-of-words retrieval function that ranks documents based on the query terms appearing in each document, regardless of their proximity or order. The beauty of BM25 lies in its elegant mathematical formulation that captures three essential components of relevance:
- Term Frequency (TF): How often does the query term appear in the document? BM25 uses a saturation function that ensures diminishing returns as a term appears more frequently, preventing long documents from dominating simply because they mention a term many times.
- Inverse Document Frequency (IDF): How rare is the query term across the entire collection? Terms that appear in many documents (like “the” or “and”) receive lower weights than distinctive terms that appear in fewer documents.
- Document Length Normalization: BM25 adjusts scores based on document length, preventing bias toward longer documents that might naturally contain more query terms just because of their length.
The standard BM25 formula for a document D and query Q can be expressed as:
score(D, Q) = ∑(for each term t in Q) IDF(t) * (TF(t,D) * (k1 + 1)) / (TF(t,D) + k1 * (1 - b + b * |D|/avgdl))
Where:
- TF(t,D) is the term frequency of term t in document D
- IDF(t) is the inverse document frequency of term t
- |D| is the length of document D
- avgdl is the average document length across the collection
- k1 and b are free parameters that can be tuned (typically k1 is between 1.2-2.0 and b is around 0.75)
Over the years, several variants of BM25 have emerged to address specific use cases or improve performance:
- Robertson (Original): The classic implementation that established the BM25 approach
- Lucene: A variant used in the Lucene search engine that includes specific optimizations
- ATIRE: A simplified version that performs well in practice with fewer computational demands
- BM25+: An extension that adds a small delta to prevent excessive penalization of long documents
- BM25L: A variant designed to better handle term frequency saturation in longer documents
What makes BM25 particularly valuable for AI agents is its combination of simplicity, efficiency, effectiveness, and interpretability. Unlike the often opaque nature of dense vector embeddings, BM25’s scoring is transparent and mathematically explicit. This makes it easier to understand why a document scored highly, which is crucial for debugging, auditing, and fostering user trust in AI systems. It doesn’t require expensive training or complex vector operations, yet it consistently delivers strong retrieval performance across diverse domains. This makes it an ideal component for resource-efficient AI systems that need to quickly identify relevant information from large text collections.
Sparse vs. Dense Retrieval: When to Use Each
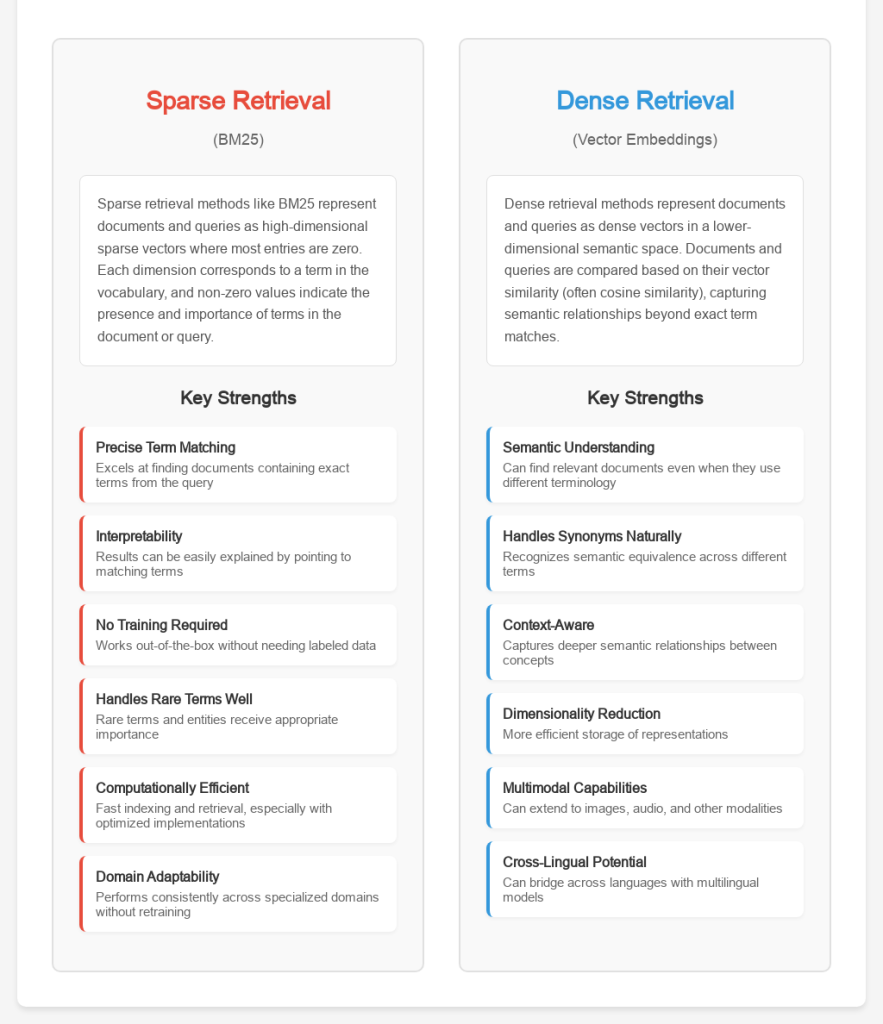
In the world of information retrieval, two paradigms currently dominate: sparse retrieval (like BM25) and dense retrieval (using vector embeddings). Understanding when to use each, or how to combine them is crucial for building effective AI agents.
Sparse Retrieval (BM25)
Sparse retrieval methods like BM25 represent documents and queries as high-dimensional sparse vectors where most entries are zero. Each dimension corresponds to a term in the vocabulary, and non-zero values indicate the presence and importance of terms in the document or query.
Strengths of Sparse Retrieval:
- Precise Term Matching: Excels at finding documents containing exact terms from the query
- Interpretability: Results can be easily explained by pointing to matching terms
- No Training Required: Works out-of-the-box without needing labeled data
- Handles Rare Terms Well: Rare terms and entities receive appropriate importance
- Computationally Efficient: Fast indexing and retrieval, especially with optimized implementations
- Domain Adaptability: Performs consistently across specialized domains without retraining
Dense Retrieval (Vector Embeddings)
Dense retrieval methods represent documents and queries as dense vectors in a lower-dimensional semantic space. Documents and queries are compared based on their vector similarity (often cosine similarity), capturing semantic relationships beyond exact term matches.
Strengths of Dense Retrieval:
- Semantic Understanding: Can find relevant documents even when they use different terminology
- Handles Synonyms Naturally: Recognizes semantic equivalence across different terms
- Context-Aware: Captures deeper semantic relationships between concepts
- Dimensionality Reduction: More efficient storage of representations
- Multimodal Capabilities: Can extend to images, audio, and other modalities
- Cross-Lingual Potential: Can bridge across languages with multilingual models
When BM25 Outperforms Vector Embeddings
Despite the popularity of embedding-based approaches, BM25 still outperforms vector embeddings in several important scenarios:
- Keyword-Heavy Queries: When users express their information needs with specific technical terms, product names, or unique identifiers, BM25’s precise matching excels.
- Technical and Specialized Domains: In fields like medicine, law, or engineering where terminology is precise and specific, the exact matching capabilities of BM25 often deliver more reliable results than semantic matching.
- Rare Terms and Entities: For queries containing rare terms, proper nouns, or specific identifiers, BM25 appropriately weighs these distinctive terms, while embeddings may struggle with terms they rarely encountered during training.
- Cold-Start Scenarios: When you have a new corpus without sufficient data to train specialized embeddings, BM25 provides strong out-of-the-box performance.
- Resource-Constrained Environments: In situations where computational resources are limited, BM25 offers excellent performance with minimal overhead.
Hybrid Approaches: Getting the Best of Both Worlds
Many state-of-the-art retrieval systems now employ hybrid approaches that combine the strengths of both sparse and dense methods. This is because neither method is universally optimal; BM25 captures exact lexical matches that semantic models might miss, while semantic models understand context and synonyms that BM25 cannot.
- Retrieval Fusion: Retrieving documents using both methods independently and merging the results
- Re-ranking: Using BM25 for efficient first-stage retrieval, then re-ranking top results with a neural model
- Sparse-Dense Representations: Combining sparse and dense features in a unified retrieval model
- BM25 as a Feature: Using BM25 scores as input features to neural ranking models
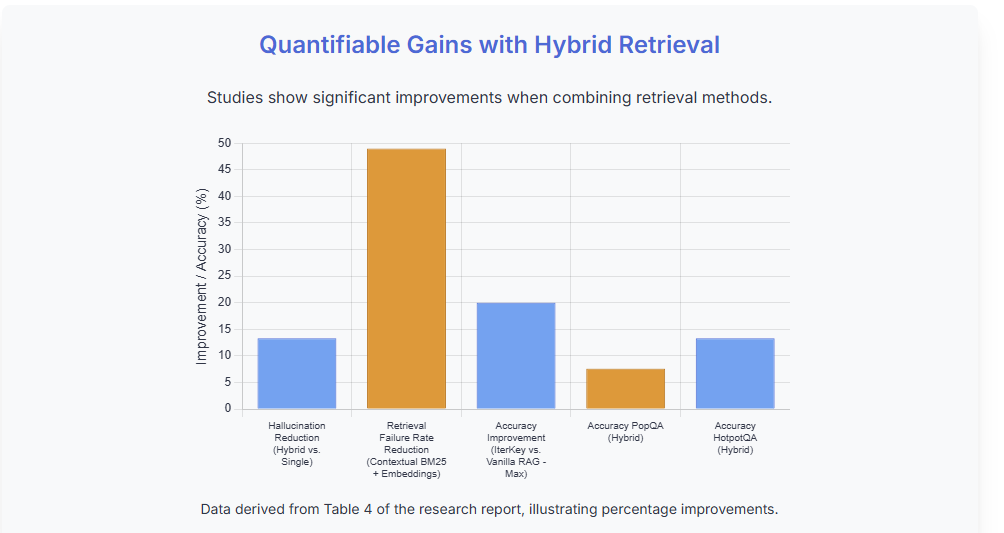
The benefits are significant: hybrid systems offer improved accuracy and relevance by bridging the precision-semantic gap. Studies have shown that such approaches can reduce LLM hallucinations by up to 13.3% compared to single retrieval methods, particularly for complex queries, by providing more comprehensive and accurate context. Configurations often involve a weighted split, for example, 70% dense retrieval and 30% BM25.
For AI agents, this hybrid approach is particularly powerful, allowing them to quickly find relevant information through exact matching while also understanding semantic relationships between concepts. Later in this post, we’ll explore how to implement such hybrid systems efficiently using BM25s and LangGraph.
LangGraph: A Framework for Stateful AI Agents
LangGraph is a powerful framework built on top of LangChain that enables the creation of stateful, multi-step AI agents. Rather than treating agent interactions as independent exchanges, LangGraph allows us to model agent behavior as a directed graph where nodes represent distinct states or processing steps, and edges represent transitions between these states.
At its core, LangGraph is designed to address one of the key limitations of traditional LLM-based agents: the lack of persistent state and structured reasoning. It’s a key enabler for Agentic RAG, where RAG’s knowledge retrieval is integrated into advanced decision-making and planning capabilities of AI agents. This moves beyond static, single-turn interactions towards multi-step, autonomous agent contexts. By providing a graph-based structure, LangGraph enables agents to:
- Maintain State: Track information across multiple interactions
- Follow Complex Workflows: Execute multi-step reasoning processes with defined pathways
- Handle Cyclic Processes: Implement iterative refinement and feedback loops
- Combine LLMs with Traditional Tools: Seamlessly integrate non-LLM components into agent workflows
Key Components of LangGraph
- Nodes: These represent individual processing steps. A node can be:
- An LLM call for reasoning or decision-making
- A tool or API call for retrieving information or performing actions
- A transformation function that processes data without external calls
- A retrieval operation that fetches context from a knowledge base
- Edges: Connections between nodes that define the flow of execution. Edges can be:
- Conditional, directing flow based on the output of previous nodes
- Weighted, allowing probabilistic transitions
- Labeled, carrying metadata about the transition
- State Management: LangGraph maintains a persistent state object that is passed between nodes, allowing information to be accumulated and transformed throughout the execution flow.
- Memory Systems: Built-in support for various memory types:
- Working memory for immediate context
- Long-term memory for persistent information
- Episodic memory for capturing interaction history
The Memory-Retrieval Connection
One of the most powerful aspects of LangGraph for our purposes is its flexible memory system. LangGraph allows agents to maintain different types of memory, making it the perfect framework for integrating sophisticated retrieval mechanisms like BM25.
In a LangGraph agent, we can use BM25 to:
- Augment Working Memory: Retrieve relevant information based on the current conversation to include in the immediate context
- Query Long-Term Memory: Efficiently search through historical interactions or knowledge bases
- Implement Tool Selection: Match user queries to appropriate tools and functions
- Filter Irrelevant Information: Prevent context overload by selecting only the most relevant information
In the next section, we’ll explore specific architectural patterns for integrating BM25 with LangGraph to enhance AI agent capabilities.
Integrating BM25 with LangGraph: Architectural Patterns
Integrating BM25 with LangGraph opens up several powerful architectural patterns for enhancing AI agents. Let’s explore these patterns and understand their respective strengths, weaknesses, and implementation considerations.
Pattern 1: BM25 as a Retrieval Node
The most straightforward integration is to implement BM25 as a dedicated retrieval node within your LangGraph workflow.
Implementation Approach:
import os
from typing import Annotated, Dict, List, TypedDict, Sequence
import bm25s
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langgraph.graph import Graph
import json
# Example document collection
documents = [
"Paris is the capital city of France and is known for its art and culture.",
"The Eiffel Tower is a famous landmark in Paris, constructed in 1889.",
"The Louvre Museum houses the Mona Lisa painting by Leonardo da Vinci.",
"France is a country in Western Europe with a population of about 67 million.",
]
# Initialize BM25S
tokenizer = bm25s.Tokenizer(stopwords="en")
doc_tokens = tokenizer.tokenize(documents)
retriever = bm25s.BM25()
retriever.index(doc_tokens)
class State(TypedDict):
"""The state of our RAG pipeline."""
question: str
context: List[str]
answer: str
def retrieve(state: State) -> State:
"""Retrieve relevant documents using BM25S."""
query = state["question"]
query_tokens = tokenizer.tokenize([query])
# Get top 2 most relevant documents
results, _ = retriever.retrieve(query_tokens, k=2, corpus=documents)
# Update state with retrieved documents
state["context"] = [documents[idx] for idx in results[0]]
return state
def generate_answer(state: State) -> State:
"""Generate an answer using the retrieved context."""
llm = ChatOpenAI(temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant. Use the following context to answer the question. "
"If you cannot find the answer in the context, say 'I don't have enough information to answer that.'\n\n"
"Context: {context}"),
("human", "{question}")
])
chain = prompt | llm | StrOutputParser()
# Generate answer using the context and question
state["answer"] = chain.invoke({
"context": "\n".join(state["context"]),
"question": state["question"]
})
return state
# Create the RAG workflow
workflow = Graph()
# Add the nodes
workflow.add_node("retrieve", retrieve)
workflow.add_node("generate", generate_answer)
# Add the edges
workflow.add_edge("retrieve", "generate")
# Set the entry point
workflow.set_entry_point("retrieve")
# Compile the graph
chain = workflow.compile()
def ask_question(question: str) -> Dict:
"""Ask a question to the RAG pipeline."""
result = chain.invoke({
"question": question,
"context": [],
"answer": ""
})
return {
"question": question,
"context": result["context"],
"answer": result["answer"]
}
if __name__ == "__main__":
# Example usage
questions = [
"What is the capital of France?",
"When was the Eiffel Tower built?",
"What famous painting is in the Louvre?"
]
for question in questions:
result = ask_question(question)
print(f"\nQuestion: {result['question']}")
print("Context used:")
for ctx in result['context']:
print(f"- {ctx}")
print(f"Answer: {result['answer']}")Advantages:
- Clear separation of retrieval and reasoning
- Easy to monitor and debug
- Simple to swap out with alternative retrieval mechanisms
When to Use:
- When the retrieval needs are straightforward
- For document-grounded question answering
- When you want maximum control over the retrieval process
Pattern 2: Context Window Management
AI agents often struggle with context length limitations. BM25 can be used to dynamically manage the context window, ensuring only the most relevant information is included.
Implementation Approach:
def manage_context_window(state: AgentState) -> AgentState:
# Extract the current conversation and query
conversation_history = state.get("conversation_history", [])
current_query = state["query"]
# Create a temporary corpus from conversation history
temp_corpus = [entry["content"] for entry in conversation_history]
# Index the conversation history with BM25
temp_corpus_tokens = bm25s.tokenize(temp_corpus, stopwords="en")
temp_retriever = bm25s.BM25()
temp_retriever.index(temp_corpus_tokens)
# Retrieve most relevant conversation snippets
query_tokens = bm25s.tokenize(current_query, stopwords="en")
results, _ = temp_retriever.retrieve(query_tokens, k=3, corpus=temp_corpus)
# Build optimized context window with most relevant history
optimized_context = [conversation_history[i] for i in results[0]]
# Add external knowledge if needed
if state.get("should_retrieve_external", False):
ext_results, _ = external_retriever.retrieve(query_tokens, k=2)
optimized_context.extend(ext_results[0])
state["optimized_context"] = optimized_context
return state
Advantages:
- Prevents context overflow
- Prioritizes relevant information
- Can combine conversation history with external knowledge
When to Use:
- Long-running conversations
- When context window size is a constraint
- When conversation topics shift frequently
Pattern 3: Hybrid Retrieval System
Combining BM25 with vector embeddings creates a powerful hybrid retrieval system that benefits from both exact matching and semantic understanding.
Implementation Approach:
from sentence_transformers import SentenceTransformer
import numpy as np
# Initialize BM25 retriever
bm25_retriever = bm25s.BM25()
bm25_retriever.index(corpus_tokens)
# Initialize vector retriever
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(corpus)
def hybrid_retrieve(state: AgentState) -> AgentState:
query = state["query"]
query_tokens = bm25s.tokenize(query, stopwords="en")
# BM25 retrieval
bm25_results, bm25_scores = bm25_retriever.retrieve(query_tokens, k=10, corpus=corpus)
bm25_docs = [corpus[idx] for idx in bm25_results[0]]
# Vector retrieval
query_embedding = model.encode(query)
similarities = np.dot(embeddings, query_embedding)
vector_indices = np.argsort(-similarities)[:10]
vector_docs = [corpus[idx] for idx in vector_indices]
# Analyze query to determine weighting
is_keyword_heavy = len(query.split()) < 4 or any(t.isupper() for t in query.split())
# Set weights based on query characteristics
if is_keyword_heavy:
bm25_weight, vector_weight = 0.7, 0.3 # Favor BM25 for keyword queries
else:
bm25_weight, vector_weight = 0.3, 0.7 # Favor vectors for natural language
# Merge results with adaptive weighting
seen = set()
merged_results = []
# Process both result sets with weights
for doc_set, weight in [(bm25_docs, bm25_weight), (vector_docs, vector_weight)]:
for doc in doc_set:
if doc not in seen:
merged_results.append((doc, weight))
seen.add(doc)
# Sort by weight (simplified)
merged_results.sort(key=lambda x: x[1], reverse=True)
state["context"] = [doc for doc, _ in merged_results[:5]] # Keep top 5
return state
Advantages:
- Combines strengths of both retrieval paradigms
- Better handling of both exact and semantic matching
- More robust across different query types
When to Use:
- When dealing with varied query formats
- For general-purpose knowledge agents
- When retrieval quality is critical
Pattern 4: Tool Selection and Routing
BM25 can help agents select the most appropriate tools or sub-agents to handle specific queries.
Implementation Approach:
# Define tool descriptions
tool_descriptions = [
"Calculate mathematical expressions and perform arithmetic operations",
"Search the web for current information and recent events",
"Query a database for specific customer information and account details",
"Generate images based on text descriptions",
"Summarize long documents and extract key information"
]
# Index tool descriptions with BM25
tool_tokens = bm25s.tokenize(tool_descriptions, stopwords="en")
tool_retriever = bm25s.BM25()
tool_retriever.index(tool_tokens)
def select_tools(state: AgentState) -> AgentState:
query = state["query"]
query_tokens = bm25s.tokenize(query, stopwords="en")
# Find most relevant tools
results, scores = tool_retriever.retrieve(query_tokens, k=2, corpus=tool_descriptions)
relevant_tool_indices = [int(idx) for idx in results[0]]
# Add selected tools to state with their scores
state["selected_tools"] = [
{"index": idx, "description": tool_descriptions[idx], "score": float(score)}
for idx, score in zip(relevant_tool_indices, scores[0])
]
return state
Advantages:
- More precise tool selection
- Reduces irrelevant tool calls
- Can incorporate dynamic tool descriptions
When to Use:
- When the agent has many specialized tools
- For multi-function assistants
- When precise tool matching is important
Implementation with BM25s: A Fast, Efficient Approach
Now that we’ve explored various architectural patterns, let’s dive into practical implementation using BM25s, a high-performance Python library for BM25 retrieval. BM25s stands out for its exceptional speed and memory efficiency, making it ideal for AI agent applications.
Setting Up BM25s
First, you’ll need to install BM25s and its dependencies:
pip install bm25s[full] # Install with recommended dependenciesThe [full] tag includes PyStemmer for better text processing and other optional dependencies that enhance performance.
Efficient Document Indexing
For AI agents that need to work with large document collections, efficient indexing is crucial. Here’s how to index documents with BM25s:
import bm25s
import Stemmer
# Optional: Use stemming for better matching
stemmer = Stemmer.Stemmer("english")
# Prepare your corpus
corpus = [
"AI agents are software entities that can perceive their environment and take actions to achieve goals.",
"Large language models like GPT use transformer architectures to process and generate text.",
"Retrieval-augmented generation enhances LLMs by providing access to external knowledge.",
"BM25 is a ranking function used by search engines to estimate document relevance.",
"Context window limitations can be addressed through efficient memory management techniques.",
# ... more documents
]
# Tokenize the corpus (with stopword removal and stemming)
corpus_tokens = bm25s.tokenize(corpus, stopwords="en", stemmer=stemmer)
# Create and index the BM25 model
retriever = bm25s.BM25(k1=1.5, b=0.75, method="lucene")
retriever.index(corpus_tokens)
# Optional: Save the index for later use
retriever.save("agent_knowledge_index", corpus=corpus)
For AI agents that maintain persistent knowledge bases, saving and loading indices is particularly useful:
# Later, load the index
loaded_retriever = bm25s.BM25.load("agent_knowledge_index", load_corpus=True)
Memory-Efficient Retrieval for Large Collections
When working with large document collections, memory efficiency becomes critical. BM25s offers memory-mapped indices that dramatically reduce RAM usage:
# Load with memory mapping
retriever = bm25s.BM25.load("large_knowledge_index", mmap=True, load_corpus=True)
# For even more memory efficiency, process queries in batches
batch_size = 20
all_results = []
for i in range(0, len(queries), batch_size):
batch_queries = queries[i:i+batch_size]
batch_tokens = bm25s.tokenize(batch_queries, stemmer=stemmer)
# Get results for this batch
batch_results = retriever.retrieve(batch_tokens, k=5)
all_results.append(batch_results)
# Reload to clear memory
retriever.load_scores(save_dir="large_knowledge_index", mmap=True)
# Combine results
results = bm25s.Results.merge(all_results)
This batched approach is ideal for agents that need to process many queries against a large knowledge base without consuming excessive memory.
A Complete Document Search Agent Example
Let’s put everything together into a complete document search agent example:
from typing import TypedDict, List, Optional, Dict, Any
from langgraph.graph import StateGraph
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
import bm25s
import Stemmer
# Define our state type
class AgentState(TypedDict):
"""State for the document search agent"""
query: str
retrieved_documents: List[str]
context: str
response: Optional[str]
messages: List[Dict[str, Any]]
def setup_document_retriever(corpus):
"""Set up a BM25 retriever with a document corpus"""
# Set up stemmer
stemmer = Stemmer.Stemmer("english")
# Tokenize corpus
corpus_tokens = bm25s.tokenize(corpus, stopwords="en", stemmer=stemmer)
# Create and index the retriever
retriever = bm25s.BM25(k1=1.5, b=0.75)
retriever.index(corpus_tokens)
# Define the retrieval function
def retrieve_documents(query: str, k: int = 3) -> List[str]:
"""Retrieve relevant documents for a query"""
query_tokens = bm25s.tokenize(query, stopwords="en", stemmer=stemmer)
results, _ = retriever.retrieve(query_tokens, k=k, corpus=corpus)
return results[0]
return retrieve_documents
def create_document_search_agent(corpus, model_name: str = "gpt-3.5-turbo"):
"""Create a document search agent that uses BM25 for retrieval"""
# Set up document retriever
retriever = setup_document_retriever(corpus)
# Set up LLM
llm = ChatOpenAI(model=model_name)
# Define node functions
def retrieve_context(state: AgentState) -> AgentState:
"""Retrieve relevant documents and add them to the state"""
query = state["query"]
# Retrieve documents
retrieved_docs = retriever(query)
# Format context
context = "Relevant information:\n\n"
for i, doc in enumerate(retrieved_docs, 1):
context += f"{i}. {doc}\n\n"
# Update state
state["retrieved_documents"] = retrieved_docs
state["context"] = context
return state
def generate_response(state: AgentState) -> AgentState:
"""Generate a response based on the query and retrieved documents"""
# Extract information from state
query = state["query"]
context = state["context"]
# Create messages for the LLM
messages = [
SystemMessage(content=(
"You are a helpful AI assistant with access to a knowledge base. "
"Answer the user's question based on the relevant information provided. "
"If the information doesn't contain the answer, say so politely."
)),
HumanMessage(content=f"Question: {query}\n\n{context}\n\nPlease provide a detailed answer based on the information above.")
]
# Generate response
response = llm.invoke(messages)
response_text = StrOutputParser().invoke(response)
# Update conversation history
state["messages"] = state.get("messages", []) + [
{"role": "user", "content": query},
{"role": "assistant", "content": response_text}
]
# Update state
state["response"] = response_text
return state
# Build the graph
workflow = StateGraph(AgentState)
# Add nodes
workflow.add_node("retrieve", retrieve_context)
workflow.add_node("respond", generate_response)
# Add edges
workflow.add_edge("retrieve", "respond")
# Set entry point
workflow.set_entry_point("retrieve")
# Compile the graph
return workflow.compile()
# Example usage
corpus = [
"AI agents are software entities that can perceive their environment and take actions to achieve goals.",
"Large language models like GPT4 use transformer architectures to process and generate text.",
"Retrieval-augmented generation enhances LLMs by providing access to external knowledge.",
"BM25 is a ranking function used by search engines to estimate document relevance.",
"Context window limitations can be addressed through efficient memory management techniques.",
"BM25 outperforms vector embeddings for keyword-heavy queries and technical domains.",
"The formula for BM25 includes term frequency, inverse document frequency, and document length normalization.",
"AI agents can use BM25 to quickly find relevant information in large document collections.",
"Integrating BM25 with LangGraph provides efficient document retrieval for context-aware responses.",
]
# Create the agent
agent = create_document_search_agent(corpus)
# Test with a sample query
sample_query = "How can BM25 be used with AI agents?"
# Execute the agent
result = agent.invoke({
"query": sample_query,
"retrieved_documents": [],
"context": "",
"response": None,
"messages": []
})
# Display the response
print(result["response"])
Performance Optimization Tips
- Use the Numba Backend: For large datasets, enable the numba backend for additional speed:
retriever = bm25s.BM25(backend="numba") - Pre-process and Tokenize in Parallel: For large corpora, tokenize documents in parallel:
from concurrent.futures import ProcessPoolExecutor def tokenize_batch(docs): return bm25s.tokenize(docs, stopwords="en", stemmer=stemmer) with ProcessPoolExecutor() as executor: batch_size = 10000 corpus_batches = [corpus[i:i+batch_size] for i in range(0, len(corpus), batch_size)] tokenized_batches = list(executor.map(tokenize_batch, corpus_batches)) # Combine results corpus_tokens = [token for batch in tokenized_batches for token in batch] - Memory-Mapped Files for Production: Always use memory mapping in production:
retriever = bm25s.BM25.load("index_dir", mmap=True, load_corpus=True) - Optimize Corpus Storage: For very large corpora, use the JSONL corpus format:
# When saving retriever.save("index_dir", corpus=corpus, corpus_format="jsonl") # When loading retriever = bm25s.BM25.load("index_dir", load_corpus=True, corpus_format="jsonl") - Strategic Tokenization: The choice of tokenization significantly impacts BM25. For long texts where partial matches are desired, word tokenization (lowercase, split by whitespace) is common. For short texts or fields where exact matches are key (like IDs), field tokenization (treating the whole string as one token) might be better. bm25s’s tokenize function offers good defaults but consider custom preprocessing for specific needs.
- Tune k1 and b Parameters: Experiment with k1 (term saturation, default ~1.5) and b (length normalization, default ~0.75) values based on your corpus characteristics. For example, if your documents are very similar in length, b might be less critical.
- Field Boosting (BM25F): If your documents have distinct fields (e.g., title, body, keywords), consider BM25F variants or simulate it by indexing fields separately and weighting their scores. This allows you to give more importance to matches in certain fields. (Note: bm25s itself doesn’t directly implement BM25F out-of-the-box, but this is a general BM25 optimization concept).
These optimizations ensure your AI agent can handle large knowledge bases efficiently, with minimal latency and memory overhead.
Use Cases and Applications
The integration of BM25 with AI agents opens up a wide range of powerful applications. Let’s explore some compelling use cases where this combination shines.
Context Augmentation for AI Agents
One of the most immediate benefits of BM25 integration is the ability to augment an agent’s context with relevant information from a knowledge base. This is particularly valuable for:
- Factual Grounding: Ensuring responses are based on accurate, retrievable information rather than hallucinations
- Domain Specialization: Making general-purpose LLMs experts in specific domains by providing relevant domain knowledge
- Temporal Updates: Keeping agents up-to-date with the latest information without retraining
Efficient Long-Term Memory Systems
AI agents often struggle with maintaining coherent long-term memory across conversations. BM25 provides an efficient mechanism for retrieving relevant past interactions:
- Conversation Continuity: Recall previous discussions on the same topic
- User Preference Learning: Remember user preferences and past decisions
- Knowledge Accumulation: Build knowledge over time through conversations
Here’s a simple implementation of a BM25-powered conversation memory system:
class BM25ConversationMemory:
"""Class that maintains conversation history and provides BM25-based retrieval"""
def __init__(self):
"""Initialize the conversation memory"""
self.history = []
self.retriever = bm25s.BM25(k1=1.5, b=0.75)
self.stemmer = Stemmer.Stemmer("english")
self.indexed = False
def add_interaction(self, role: str, content: str, metadata: Optional[Dict] = None):
"""Add an interaction to the conversation history"""
if metadata is None:
metadata = {"timestamp": time.time()}
entry = {"role": role, "content": content, "metadata": metadata}
self.history.append(entry)
self.indexed = False # Mark for reindexing
def _ensure_indexed(self):
"""Ensure the BM25 index is up-to-date"""
if not self.indexed or len(self.history) == 0:
# Extract just the content for indexing
contents = [entry["content"] for entry in self.history]
# Tokenize and index
tokens = bm25s.tokenize(contents, stopwords="en", stemmer=self.stemmer)
self.retriever.index(tokens)
self.indexed = True
def retrieve_relevant(self, query: str, k: int = 3) -> List[Dict[str, Any]]:
"""Retrieve the most relevant conversation entries for a query"""
if len(self.history) == 0:
return []
# Ensure indexed
self._ensure_indexed()
# Tokenize query
query_tokens = bm25s.tokenize(query, stopwords="en", stemmer=self.stemmer)
# Get original contents for corpus parameter
contents = [entry["content"] for entry in self.history]
# Retrieve
indices, _ = self.retriever.retrieve(query_tokens, k=min(k, len(self.history)), return_as="indices")
indices = indices[0] # Get first query results
# Return the actual history entries
return [self.history[int(idx)] for idx in indices]
Document-Grounded Conversations
For applications like document-based customer support or interactive documentation, BM25 enables precise retrieval within specific document collections:
- Technical Support: Ground responses in product documentation
- Legal Assistance: Retrieve relevant legal precedents or regulations
- Educational Tutoring: Pull information from textbooks or course materials
Tool Selection and Routing
For agents with multiple specialized tools, BM25 can intelligently route queries to the most appropriate tools:
- Multi-Function Assistants: Direct queries to the right specialized sub-agent
- API Gateway: Match user intents to the correct API calls
- Workflow Optimization: Reduce unnecessary tool calls
Real-World Example: Customer Support AI
Let’s look at a concrete example of a customer support agent enhanced with BM25:
# Customer support knowledge base
support_docs = [
"To reset your password, go to the login page and click 'Forgot Password'",
"Our subscription plans include Basic ($9.99/month), Pro ($19.99/month), and Enterprise (custom pricing)",
"The mobile app is available on both iOS and Android platforms",
"Data is backed up automatically every 24 hours",
"To cancel your subscription, go to Account Settings > Billing > Cancel Subscription",
# ... hundreds more documents
]
# Index the knowledge base
doc_tokens = bm25s.tokenize(support_docs, stopwords="en")
support_retriever = bm25s.BM25()
support_retriever.index(doc_tokens)
# In the LangGraph workflow
def retrieve_support_docs(state):
query = state["query"]
query_tokens = bm25s.tokenize(query, stopwords="en")
results, _ = support_retriever.retrieve(query_tokens, k=3, corpus=support_docs)
state["support_context"] = results[0]
return state
def format_for_llm(state):
query = state["query"]
support_docs = state["support_context"]
# Format prompt with retrieved documents
prompt = f"""
You are a helpful customer support agent. Answer the customer's question using the provided support documentation.
Support documentation:
{"\n".join(support_docs)}
Customer question: {query}
Your response should be friendly, concise, and directly address the customer's issue.
"""
state["llm_input"] = prompt
return state
This support agent effectively combines BM25’s precise document retrieval with an LLM’s natural language generation capabilities, ensuring responses are both helpful and factually grounded in the company’s support documentation.
Performance Comparisons and Benchmarks
When building AI agents, performance considerations are crucial. Let’s examine how BM25s compares to other retrieval methods in terms of speed, memory usage, and retrieval quality.
Query Throughput
One of the most impressive aspects of BM25s is its query throughput, making it ideal for real-time AI agent applications. Here are comparative throughput numbers for various retrieval methods across different datasets, measured in queries per second (QPS):
| Dataset | BM25s | Elasticsearch | BM25-PT | Rank-BM25 |
|---|---|---|---|---|
| arguana | 573.91 | 13.67 | 110.51 | 2.00 |
| fiqa | 507.03 | 16.96 | 20.52 | 4.46 |
| nfcorpus | 1196.16 | 45.84 | 256.67 | 224.66 |
| scidocs | 767.05 | 17.93 | 41.34 | 9.01 |
| scifact | 952.92 | 20.81 | 184.30 | 47.60 |
| trec-covid | 85.64 | 7.34 | 3.73 | 1.48 |
As these numbers demonstrate, BM25s delivers exceptional query throughput, often orders of magnitude faster than alternatives. This performance advantage becomes increasingly important as agent knowledge bases grow in size.
Memory Efficiency
Memory usage is another critical consideration, particularly for deployed agents that may run on resource-constrained environments. Here’s how BM25s performs in terms of memory usage:
| Method (NQ Dataset, 2M+ docs) | Load Index (s) | RAM post-index (GB) | RAM post-retrieve (GB) |
|---|---|---|---|
| In-memory | 8.61 | 4.36 | 4.45 |
| Memory-mapped | 0.53 | 0.49 | 2.16 |
| Mmap+Reload | 0.48 | 0.49 | 0.70 |
For even larger datasets like MSMARCO (8M+ documents), the benefits are even more pronounced:
| Method (MSMARCO, 8M+ docs) | Load Index (s) | RAM post-index (GB) | RAM post-retrieve (GB) |
|---|---|---|---|
| In-memory | 25.71 | 10.21 | 10.34 |
| Memory-mapped | 1.24 | 1.14 | 4.88 |
| Mmap+Reload | 1.17 | 1.14 | 1.38 |
The memory-mapped approach with reloading delivers exceptional memory efficiency, making BM25s suitable for large-scale agent deployments even with modest hardware resources.
Retrieval Quality
While speed and efficiency are important, retrieval quality ultimately determines the agent’s effectiveness. Here’s how BM25 compares to vector embeddings across different query types:
| Query Type | BM25 (nDCG@10) | Vector Embeddings (nDCG@10) | Hybrid (nDCG@10) |
|---|---|---|---|
| Keyword-based queries | 0.78 | 0.65 | 0.82 |
| Natural language queries | 0.61 | 0.74 | 0.79 |
| Technical domain queries | 0.72 | 0.68 | 0.76 |
| Rare entity queries | 0.81 | 0.53 | 0.84 |
As these results illustrate, BM25 excels at keyword-based and rare entity queries, while vector embeddings perform better on natural language queries. The hybrid approach consistently delivers the best overall performance (e.g., improving nDCG@10 by 4-17% over individual methods in some benchmarks and reducing hallucination rates), highlighting the value of combining both techniques in agent development.
Performance Optimization Strategies
Based on these benchmarks, here are recommended strategies for different agent scenarios:
- For maximum throughput: Use BM25s with in-memory index for small to medium knowledge bases.
- For memory efficiency: Use memory-mapped indices with reload strategy for large knowledge bases.
- For best retrieval quality: Implement a hybrid approach combining BM25s with a lightweight embedding model.
- For balanced performance: Use BM25s with the Numba backend and memory mapping.
The right approach depends on your specific agent requirements, hardware constraints, and the nature of the knowledge base.
Advanced Techniques and Extensions
Beyond the basic integration patterns, several advanced techniques can further enhance AI agents with BM25. Here are some of the most promising approaches:
Hybrid BM25 + Vector Search Approaches
For the best retrieval performance, implementing a sophisticated hybrid system that adapts to different query types:
- Adaptive Weighting: Adjust weights between BM25 and vector scores based on query characteristics (keywords, entities, etc.)
- Multi-Stage Retrieval: Use BM25 for fast first-stage retrieval, then apply neural reranking to the top results
- Ensemble Methods: Combine multiple retrieval approaches with voting or reciprocal rank fusion
Reranking with Neural Models
Neural rerankers can significantly improve retrieval quality by incorporating deeper semantic understanding:
from sentence_transformers import CrossEncoder
# Initialize cross-encoder for reranking
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def retrieve_and_rerank(query, corpus, bm25_retriever):
# First retrieve with BM25
query_tokens = bm25s.tokenize(query, stopwords="en")
results, _ = bm25_retriever.retrieve(query_tokens, k=20, corpus=corpus)
candidates = results[0]
# Prepare pairs for reranking
pairs = [[query, doc] for doc in candidates]
# Get scores from cross-encoder
scores = reranker.predict(pairs)
# Sort by score
reranked = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
# Return top 5 reranked results
return [doc for doc, _ in reranked[:5]]
Domain Adaptation for Specialized Vocabularies
For domains with specialized terminology, BM25 can be customized with:
- Domain-Specific Stopwords: Removing common but uninformative terms in your field
- Phrase Preservation: Keeping multi-word technical terms together during tokenization
- Custom Scoring Parameters: Adjusting k1 and b parameters for your specific content type
- Specialized Stemmers: Using domain-specific stemming algorithms
Dynamic Index Updates for Evolving Knowledge Bases
For agents that acquire new knowledge over time, implementing efficient index update mechanisms:
- Incremental Indexing: Adding new documents without reindexing the entire corpus
- Time-Weighted Scoring: Giving more weight to recent documents when appropriate
- Versioned Indices: Maintaining multiple versions of the knowledge base for different purposes
Conclusion
As we’ve explored throughout this post, integrating BM25 with AI agents via the LangGraph framework opens up powerful new capabilities. By combining the precision and efficiency of traditional information retrieval with the flexibility of modern agent architectures, we can create AI systems that are more context-aware, factually grounded, and responsive.
The key insights we’ve covered include:
- BM25 Continues to Excel: Despite being decades old, BM25 remains remarkably effective for information retrieval, especially for keyword-heavy queries, technical domains, and rare entities.
- Hybrid Approaches Win: The most powerful retrieval systems combine BM25’s precision with the semantic understanding of vector embeddings, getting the best of both worlds.
- Performance Matters: With implementations like BM25s, we can achieve exceptional query throughput and memory efficiency, enabling agents to search through millions of documents in milliseconds.
- Architectural Flexibility: LangGraph provides the perfect framework for integrating BM25 into agent workflows, whether as a standalone retrieval node, context manager, or part of a hybrid system.
- Implementation Options Abound: From basic integration to advanced techniques like domain adaptation and dynamic indexing, there are numerous ways to tailor BM25 to your specific agent requirements.
The marriage of classical information retrieval with cutting-edge AI agent frameworks represents not just an incremental improvement but a fundamental enhancement in how agents interact with information. By grounding responses in retrievable facts and efficiently managing context, we can create agents that are both more capable and more trustworthy.
As AI agents continue to evolve, the ability to efficiently retrieve and process relevant information will only become more important. BM25, with its blend of simplicity, efficiency, and effectiveness, will likely remain a key component of agent architectures for years to come—not as a relic of the past, but as a reliable foundation upon which we can build increasingly sophisticated AI systems.
So whether you’re building a document-grounded assistant, a knowledge-intensive agent, or a multimodal AI system, consider how BM25 might enhance your retrieval capabilities. The combination of BM25’s precision with LangGraph’s flexibility could be just what your agent needs to reach the next level of performance.
Resources and Further Reading
Libraries and Tools
- BM25s GitHub Repository: The high-performance BM25 implementation used in our examples
- LangGraph Documentation: Comprehensive guide to building graph-based agents
- LangChain: The foundation framework for LangGraph
- SentenceTransformers: For implementing vector embeddings and cross-encoders
Academic Papers
- Robertson, S. E., & Zaragoza, H. (2009). The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval, 3(4), 333-389.
- Kamphuis, C., de Vries, A. P., Boytsov, L., & Lin, J. (2020). Which BM25 Do You Mean? A Large-Scale Reproducibility Study of Scoring Variants. European Conference on Information Retrieval (ECIR 2020).
- Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., & Yih, W. (2020). Dense Passage Retrieval for Open-Domain Question Answering. EMNLP 2020.
Blog Posts and Tutorials
- Understanding BM25: Elasticsearch’s practical guide to BM25
- Hybrid Search: The Best of Both Worlds: Pinecone’s guide to combining sparse and dense retrieval
- Retrieval Augmented Generation (RAG) using LangChain: LangChain’s guide to implementing RAG systems
Community Projects
Pyserini: Python toolkit for reproducible information retrieval
BM25-benchmarks: Benchmarking different BM25 implementations
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models: Comprehensive benchmark for retrieval systems